먼저 csv파일을 불러오고 train 데이터와 test 데이터를 나눠주겠다.
- 데이터 불러오기
import pandas as pd
df = pd.read_csv("./drive/MyDrive/basketball_stat.csv") #구글 드라이브 내에 있는 파일을 불러옴
df.head()
- 데이터 분리
from sklearn.model_selection import train_test_split
#80%는 학습 데이터, 20%는 테스트 데이터로 분리
train, test = train_test_split(df, test_size=0.2)
#학습 데이터, 테스트 데이터 개수 확인
print(train.shape[0])
print(test.shape[0])최적의 SVM 파라미터 찾기
이제 불러온 데이터를 RBF 커널을 사용하여 실습을 할 것인데 그 전에 최적의 비용(C)와 감마(gamma)값을 찾아야한다. 이 때 이 두개의 파라미터 값을 그리드 서치(grid search)를 사용하여 찾을 것이다.
from sklearn.model_selection import GridSearchCV # 그리드 서치 사용
from sklearn.metrics import classification_report, accuracy_score # 분류 실행 결과 report를 보여주는 classification_report, 정확도 점수(accuracy_score)
from sklearn.svm import SVC # SVM 모델
import numpy as np
def svc_param_selection(X, y, nfolds): #nfolds는 교차 검증 수를 의미한다
svm_parameters = [
{'kernel' : ['rbf'],
'gamma' : [0.00001, 0.0001, 0.001, 0.01, 0.1, 1],
'C' : [0.01, 0.1, 1, 10, 100, 1000]}
]
#사이킷런에서 제공하는 GridSearchCV를 사용해 최적의 파라미터를 구함
clf = GridSearchCV(SVC(), svm_parameters, cv=nfolds, scoring='accuracy') # estimator, param_grid, cross-validation
clf.fit(X_train, y_train.values.ravel())
print(clf.best_params_) #최고 점수를 낸 파라미터 출력
return clf
#3점숫과 블로킹 획수를 학습 데이터로 사용
X_train = train[['3P', 'BLK']]
#농구선수 포지션을 예측값으로 선정
y_train = train[['Pos']]
#최적의 파라미터로 학습된 모델을 clf로 저장
clf = svc_param_selection(X_train, y_train.values.ravel(), 10)위 코드에서 주의깊게 봐야할 것이 GridSearchCV 함수이다. 인자 값으로 estimator, param_grid, cross-validation, scoring 등을 지정하는데 param_grid에는 비용, 감마 값이 될 후보들을 dictionary 형식으로 지정하고 cross-validation은 교차 검증을 수행하기 위한 숫자 값을 지정하는 것이다. estimator는 보듯이 사용할 모델을 지정하고 scoring는 어떤 점수를 기준으로 할 것이냐를 지정하는 것이다.
이렇게 인자 값을 지정하고 train 데이터를 학습하면 각 비용과 감마 값을 하나씩 집어 넣어보고 교차 검증까지 수행한다. 그리고 best_params_함수를 사용하여 가장 최적의 비용과 감마 값을 알아낼 수 있다.
[출력]
{'C': 1, 'gamma': 1, 'kernel': 'rbf'}결정 경계선 시각화
import matplotlib.pyplot as plt
# 시각화할 비용 후보들을 저장
C_candidates = []
C_candidates.append(clf.best_params_['C'] * 0.01)
C_candidates.append(clf.best_params_['C'])
C_candidates.append(clf.best_params_['C'] * 100)
# 시각화할 감마 후보들을 저장
gamma_candidates = []
gamma_candidates.append(clf.best_params_['gamma'] * 0.01)
gamma_candidates.append(clf.best_params_['gamma'])
gamma_candidates.append(clf.best_params_['gamma'] * 100)
# 3점슛과 블로킹 횟수로 학습
X = train[['3P', 'BLK']]
#농구선수 포지션을 학습 모델의 분류값으로 사용
Y = train['Pos'].tolist()
#시각화를 위해 센터(c)와 슈팅가드(SG)를 숫자로 표현
position = []
for gt in Y:
if gt == 'C':
position.append(0)
else:
position.append(1)
classifiers = []
# 파라미터 후보들을 조합해서 학습된 모델들을 저장
for C in C_candidates:
for gamma in gamma_candidates:
clf = SVC(C=C, gamma=gamma)
clf.fit(X, Y)
classifiers.append((C, gamma, clf))
#각 모델을 시각화
plt.figure(figsize=(18, 18))
xx, yy = np.meshgrid(np.linspace(0, 4, 100), np.linspace(0, 4, 100))
for (k, (C, gamma, clf)) in enumerate(classifiers):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) # np.c_[xx.ravel(), yy.ravel()]에 대한 신뢰도 예측 -> (10000,)
Z = Z.reshape(xx.shape) # (100, 100)
plt.subplot(len(C_candidates), len(gamma_candidates), k + 1)
plt.title("gamma=10^%d, C=10^%d" % (np.log10(gamma), np.log10(C)),
size='medium')
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.RdBu) # Z의 값을 RdBu colormap에 매핑됨
plt.scatter(X['3P'], X['BLK'], c=position, cmap=plt.cm.RdBu_r, edgecolors='k')여기서는 각 파라미터 후보들을 학습한 모델을 저장하고 시각화하는 부분만 조금 신경써서 보면 될 것 같다.
- np.linespace(0,4,100)는 0에서 4까지 100등분을 한다는 의미이다.
- clf.decision_function는 지정한 데이터에 대한 신뢰도를 예측한다. 간단히 말하면 X와 Y값을 양수와 음수로 판단하여 실수 값으로 반환한다는 것이다. 그리고 반환한 값의 shape은 (n,)으로 나온다.
- np.c_[xx.ravel(), yy.ravel()]에서 np.c_는 하나의 colmn으로 함치는 함수이다. 즉, (100,)와 (100,)이 (10000,)으로 합쳐진다는 것이다.
- pcolormesh에서 집어넣은 Z값은 RdBu라는 colormap에 매핑되어 나타난다. 예를 들어서 값이 [0.8, 1, 1.5]가 있다면 0.8은 red에 가깝게, 1은 white에 가깝게, 1.5는 blue에 가깝게 매핑될 것이다.

[출력]
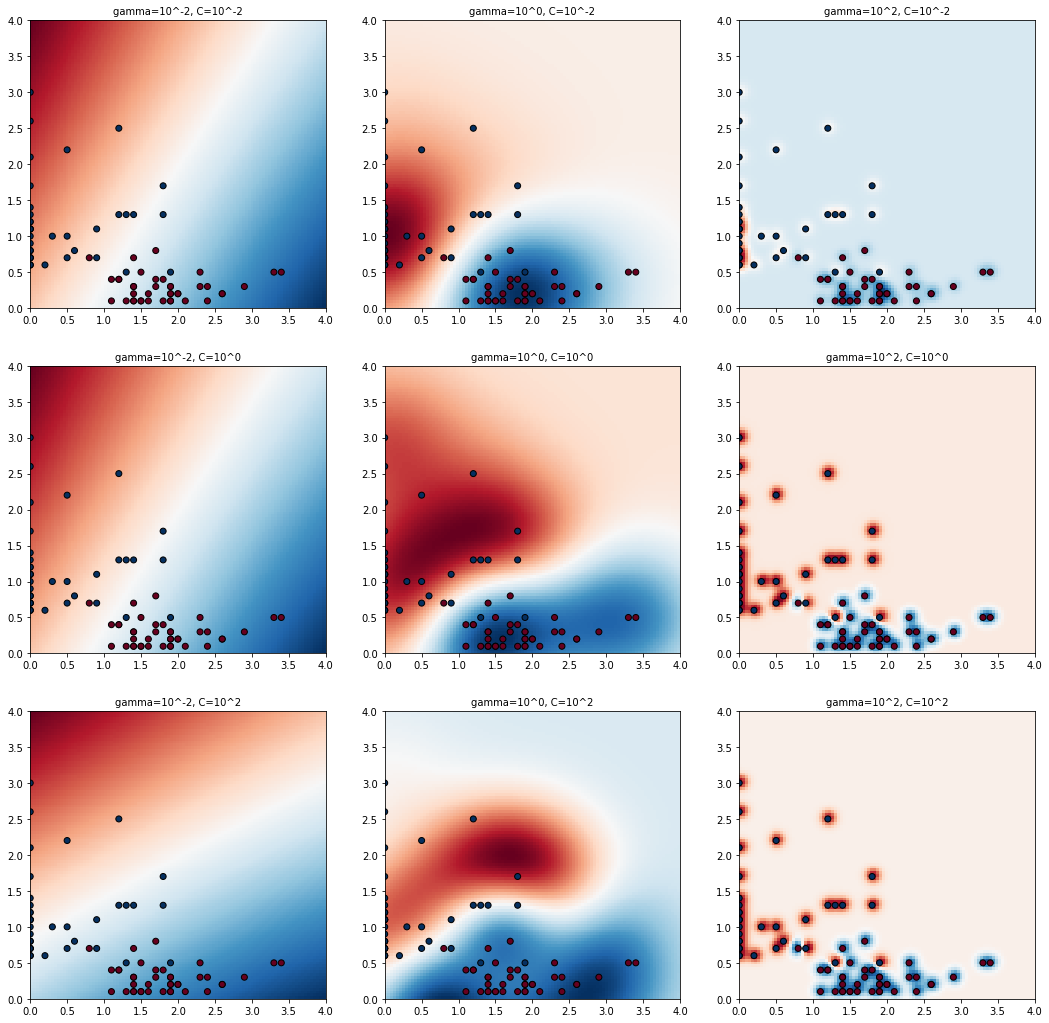
모델 테스트
X_test = test[['3P', 'BLK']]
y_test = test[['Pos']]
# 최적의 파라미터로 학습된 모델로 테스트를 진행
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred))
print("accuracy :", str(accuracy_score(y_true, y_pred))) # 실제 값과 예측 값에 대한 정확도 점수classification_report를 사용하여 분류 결과에 대한 report를 출력하고 accuracy_score를 사용하여 정확도를 출력한다.
[출력]
precision recall f1-score support
C 1.00 0.90 0.95 10
SG 0.91 1.00 0.95 10
accuracy 0.95 20
macro avg 0.95 0.95 0.95 20
weighted avg 0.95 0.95 0.95 20
accuracy : 0.95comparison = pd.DataFrame({'prediction':y_pred,
'ground_truth':y_true.values.ravel()})
comparison실제 예측한 값을 확인하면 다음과 같다.
[출력]

이렇게 [https://github.com/wikibook/machine-learning]에서 다운로드 받은 농구선수에 대한 데이터를 사용하여 SVM 알고리즘을 적용해보는 실습을 마친다.
'Machine Learning > Coding' 카테고리의 다른 글
| [실습]Bernoulli Naive Bayes(베르누이 나이브 베이즈) (0) | 2021.06.10 |
|---|---|
| [실습] Gaussian Naive Bayes(가우시안 나이브 베이즈) (0) | 2021.06.07 |
| [실습]의사결정 트리(Decision Tree) (3) | 2021.06.01 |
| [실습] k-최근접 이웃(k-Nearest Neighbor, kNN) (0) | 2021.05.22 |
| COVID-19 데이터 가공 및 시각화 (0) | 2021.05.20 |