728x90
Import
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB #베르누이 나이브 베이즈
from sklearn.metrics import accuracy_score'CountVectorizer'에 대한 것은 사용할 때 설명하겠다.
데이터 생성
#임의의 데이터 생성
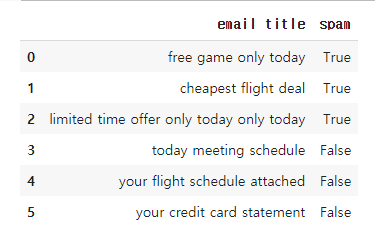
email_list = [
{'email title' : 'free game only today', 'spam' : True},
{'email title' : 'cheapest flight deal', 'spam' : True},
{'email title' : 'limited time offer only today only today', 'spam' : True},
{'email title' : 'today meeting schedule', 'spam' : False},
{'email title' : 'your flight schedule attached', 'spam' : False},
{'email title' : 'your credit card statement', 'spam' : False}]
df = pd.DataFrame(email_list)
df [출력]
데이터 전처리
'CountVectorizer'를 사용하면 특정 데이터 안의 모든 단어를 포함한 고정 길이 벡터를 만들 수 있다. 고정 길이 벡터를 만들어야하는 이유는 베르누이 나이브 베이즈의 입력 데이터가 고정된 크기의 벡터여야 하기 때문이다. 'CountVectorizer'를 생성할 때 binary = True를 설정하면 이메일 제목에 특정 단어가 출현할 경우 무조건 1을, 단어가 출현하지 않을 경우에는 0을 갖도록 설정된다.
# 베르누이 나이브 베이즈는 숫자만 다루기 때문에 True와 False를 1과 0으로 치환
df['label'] = df['spam'].map({True:1, False:0})
#학습 데이터, 레이블(label) 분리
df_x = df["email title"]
df_y = df["label"]
# 고정된 크기의 벡터로 변환
cv = CountVectorizer(binary=True)
x_traincv = cv.fit_transform(df_x)
encoded_input = x_traincv.toarray()
encoded_input[출력]

위 출력 내용을 보면 총 17개의 단어가 발견되어 각 이메일 제목이 17개 크기의 벡터로 인코딩된 것을 확인할 수 있다. 또한 이메일 제목에 중복된 단어가 있더라도 중복된 횟수로 표현된 것이 아닌 단순히 1로 표현된 것을 확인할 수 있다. 예를 들어 'limited time offer only today only today'에서 'only'와 'today'가 두 번 반복되지만 1로 표현된 것을 볼 수 있다.
# 고정된 크기의 벡터에 포함되어있는 단어들 확인
print(cv.inverse_transform(encoded_input[0]))
# 각 인덱스에 해당하는 단어 확인
print(cv.get_feature_names())[출력]
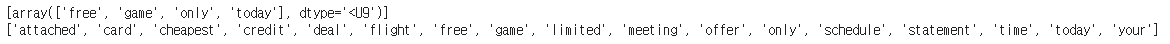
모델 학습
사이킷런의 베르누이 나이브 베이즈는 기본적으로 스무딩을 지원하므로 학습 데이터에 없던 단어가 테스트 데이터에 있어도 분류가 잘 진행된다.
bnb = BernoulliNB()
bnb.fit(x_traincv, df_y)[출력]
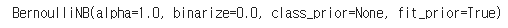
테스트 데이터 생성
test_email_list = [
{'email title' : 'free flight offer', 'spam' : True},
{'email title' : 'hey traveler free flight deal', 'spam' : True},
{'email title' : 'limited free game offer', 'spam' : True},
{'email title' : 'today flight schedule', 'spam' : False},
{'email title' : 'your credit card attached', 'spam' : False},
{'email title' : 'your credit card offer only today', 'spam' : False}]
test_df = pd.DataFrame(test_email_list)
test_df['label'] = test_df['spam'].map({True:1, False:0})
test_x = test_df['email title']
test_y = test_df['label']
x_testcv = cv.transform(test_x)테스트 데이터는 fit할 필요가 없으므로 그냥 cv.transform으로 벡터 변환을 실행했다.
테스트
predictions = bnb.predict(x_testcv)
predictions[출력]
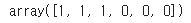
# 정확도 확인
accuracy_score(test_y, predictions)[출력]
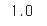
정확도가 1.0이 나왔다.... 테스트 데이터가 너무 간단해서 그런건가.... 성능이 좋은건가...
728x90
'Machine Learning > Coding' 카테고리의 다른 글
| [실습] 랜덤 포레스트(Random Forest)와 앙상블(Ensemble) (0) | 2021.06.20 |
|---|---|
| [실습] 다항분포 나이브 베이즈(Multinomial Naive Bayes) (0) | 2021.06.13 |
| [실습] Gaussian Naive Bayes(가우시안 나이브 베이즈) (0) | 2021.06.07 |
| [실습]의사결정 트리(Decision Tree) (3) | 2021.06.01 |
| [실습]SVM(Support Vector Machine) (2) | 2021.05.27 |