랜덤 포레스트 모델을 사용하여 손글씨 분류를 실습해보았다.
랜덤 포레스트 손글씨 분류
Import
from sklearn import datasets, tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np데이터 불러오기
mnist = datasets.load_digits()
features, labels = mnist.data, mnist.target
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size = 0.2)train_test_split를 사용하여 학습데이터와 테스트데이터를 나누었다.
교차 검증(cross-validation)
def cross_validation(classifier, features, labels):
cv_scores = []
for i in range(10):
scores = cross_val_score(classifier, features, labels, cv=10, scoring='accuracy')
cv_scores.append(scores.mean())
return cv_scores
dt_cv_scores = cross_validation(tree.DecisionTreeClassifier(), features, labels) #의사결정 트리의 정확도
print(dt_cv_scores)
rf_cv_scores = cross_validation(RandomForestClassifier(), features, labels) #랜덤 포레스트의 정확도
print(rf_cv_scores)cv는 10으로 지정하여 10번의 교차 검증을 실행한다.
[출력]
[0.821921166977033, 0.8174487895716945, 0.8341651148355058, 0.8252513966480446, 0.8330446927374302, 0.8263718187461204, 0.8219118559900684, 0.8263749224084419, 0.8224736188702669, 0.8285940409683427] [0.9465735567970205, 0.9515797641216635, 0.9460273122284295, 0.9510117939168218, 0.9471260086902543, 0.951024208566108, 0.9454624456859093, 0.9460117939168218, 0.9460335195530725, 0.9521322160148975]
랜덤 포레스트와 의사결정 트리의 정확도 시각화
cv_list = [
['random_forest', rf_cv_scores],
['decision_tree', dt_cv_scores]
]
df = pd.DataFrame.from_dict(dict(cv_list))
df.plot()[출력]
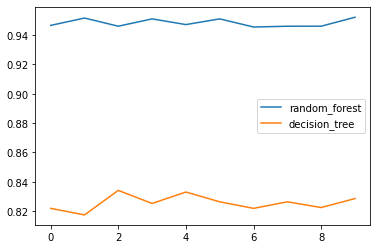
정확도 확인
#의사결정 트리의 정확도
print(np.mean(dt_cv_scores))
#랜덤 포레스트의 정확도
print(np.mean(rf_cv_scores))[출력]

모델 학습
이제 랜덤 포레스트 모델을 사용하여 학습을 시켜보자.
clf = RandomForestClassifier()
clf.fit(X_train, y_train)[출력]

테스트
pred = clf.predict(X_test)
print("accuracy :", str(accuracy_score(y_test, pred)))[출력]
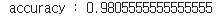
보팅 앙상블 손글씨 분류
Import
위에서 이미 import한 라이브러리를 제외한 나머지 라이브러리를 import 한다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier단일 모델의 정확도 측정
#의사결정 트리
dtree = tree.DecisionTreeClassifier(criterion='gini', max_depth=8, max_features=32, random_state=35)
dtree = dtree.fit(X_train, y_train)
dtree_predicted = dtree.predict(X_test)
#KNN
knn = KNeighborsClassifier(n_neighbors=299).fit(X_train, y_train)
knn_predicted = knn.predict(X_test)
#SVM
svm = SVC(C=0.1, gamma=0.003, probability=True, random_state=35).fit(X_train, y_train)
svm_predicted = svm.predict(X_test)
print("[accuracy]")
print("d_tree: ", accuracy_score(y_test, dtree_predicted))
print("knn : ", accuracy_score(y_test, knn_predicted))
print("svm : ", accuracy_score(y_test, svm_predicted))[출력]

분류값별 확률 확인
직접 소프트 보팅을 구현할 때는 predict_proba 함수를 사용해 테스트를 수행할 때 측정된 분류값별 확률을 사용하면 됩니다. 아래 SVM으로부터 나온 테스트 데이터 2개의 0부터 9까지의 확률을 볼 수 있다. 또한 0부터 9까지의 확률을 더하면 1이 되는 것을 확인 할 수 있다.
svm_proba = svm.predict_proba(X_test)
print(svm_proba[0:2])
print(sum(svm_proba[0]))[출력]
하드 보팅
voting_clf = VotingClassifier(estimators=[
('decision_tree', dtree), ('knn', knn), ('svm', svm)],
weights=[1,1,1], voting='hard').fit(X_train, y_train)
hard_voting_predicted = voting_clf.predict(X_test)
accuracy_score(y_test, hard_voting_predicted)직관적으로 voting='hard'를 보고 하드 보팅이라는 것을 알 수 있을 것이다.
[출력]

소프트 보팅
voting_clf = VotingClassifier(estimators=[
('decision_tree', dtree), ('knn', knn), ('svm', svm)],
weights=[1,1,1], voting='soft').fit(X_train, y_train)
soft_voting_predicted = voting_clf.predict(X_test)
accuracy_score(y_test, soft_voting_predicted)소프트 보팅도 마찬가지로 voting='soft'라고 지정해준다.
[출력]

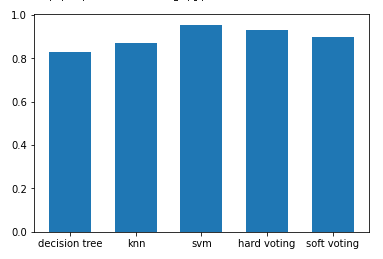
단일 모델과 앙상블 모델의 정확도 비교 시각화
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 5, 5)
plt.bar(x, height=[accuracy_score(y_test, dtree_predicted),
accuracy_score(y_test, knn_predicted),
accuracy_score(y_test, svm_predicted),
accuracy_score(y_test, hard_voting_predicted),
accuracy_score(y_test, soft_voting_predicted)])
plt.xticks(x, ['decision tree', 'knn', 'svm', 'hard voting', 'soft voting'])[출력]
'Machine Learning > Coding' 카테고리의 다른 글
| [실습] Linear Regression(선형회귀) (0) | 2021.06.27 |
|---|---|
| [실습] KMeans (K 평균 군집화) (0) | 2021.06.23 |
| [실습] 다항분포 나이브 베이즈(Multinomial Naive Bayes) (0) | 2021.06.13 |
| [실습]Bernoulli Naive Bayes(베르누이 나이브 베이즈) (0) | 2021.06.10 |
| [실습] Gaussian Naive Bayes(가우시안 나이브 베이즈) (0) | 2021.06.07 |