728x90
Import
다음과 같이 필요한 라이브러리를 임포트한다.
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#가우시안 나이브 베이즈
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
from sklearn.metrics import accuracy_score데이터 불러오기
각 데이터 속성의 뜻은 다음과 같다.
sepal length : 꽃받침 길이
sepal width : 꽃받침 너비
petal length : 꽃잎 길이
petal width : 꽃잎 너비
target : 붓꽃의 종류
# iris 데이터 불러오기
dataset = load_iris()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df['target'] = dataset.target #target 칼럼을 추가
df.target = df.target.map({0:"setosa", 1:"versicolor", 2:"virginica"}) # 숫자 형태의 target 값을 문자로 변경
df.head()[출력]

데이터 시각화
# 붖꽃의 종류별로 데이터 프레임을 나눈다
setosa_df = df[df.target == 'setosa']
versicolor_df = df[df.target == 'versicolor']
virginica_df = df[df.target == 'virginica']
#setosa 붖꽃의 꽃받침의 길이에 따른 분포도를 다음과 같이 시각화할 수 있다
ax = setosa_df['sepal length (cm)'].plot(kind='hist')
setosa_df['sepal length (cm)'].plot(kind='kde', ax=ax, secondary_y=True, title='setosa sepal length (cm) distribution', figsize = (8,4))[출력]

이후 각 붖꽃에 대한 꽃받침 길이, 너비의 분포도를 시각화하면 다음과 같다
꽃받침 길이

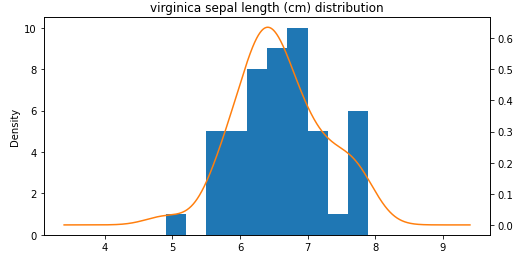
꽃받침 너비



꽃잎 길이


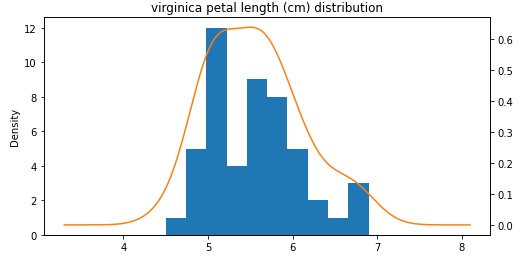
꽃잎 너비



데이터 나누기
X_train, X_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=0.2) # 데이터 나누기가우시안 나이브 베이즈 모델 학습
model = GaussianNB()
model.fit(X_train, y_train)[출력]
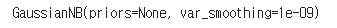
테스트
predicted = model.predict(X_test)
print(metrics.classification_report(y_test, predicted))[출력]

accuracy_score(y_test, predicted)[출력]

728x90
'Machine Learning > Coding' 카테고리의 다른 글
| [실습] 다항분포 나이브 베이즈(Multinomial Naive Bayes) (0) | 2021.06.13 |
|---|---|
| [실습]Bernoulli Naive Bayes(베르누이 나이브 베이즈) (0) | 2021.06.10 |
| [실습]의사결정 트리(Decision Tree) (3) | 2021.06.01 |
| [실습]SVM(Support Vector Machine) (2) | 2021.05.27 |
| [실습] k-최근접 이웃(k-Nearest Neighbor, kNN) (0) | 2021.05.22 |