728x90
한글 폰트 사용을 위해 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf한글 폰트를 따로 설치해주지 않으면 한글이 '□□□□'로 깨져서 나온다.
[출력]
Reading package lists... Done
Building dependency tree
Reading state information... Done
fonts-nanum is already the newest version (20170925-1).
The following package was automatically installed and is no longer required:
libnvidia-common-460
Use 'sudo apt autoremove' to remove it.
0 upgraded, 0 newly installed, 0 to remove and 34 not upgraded.
/usr/share/fonts: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 3 dirs
/usr/share/fonts/truetype/humor-sans: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
/usr/share/fonts/truetype/nanum: caching, new cache contents: 10 fonts, 0 dirs
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
/root/.local/share/fonts: skipping, no such directory
/root/.fonts: skipping, no such directory
/var/cache/fontconfig: cleaning cache directory
/root/.cache/fontconfig: not cleaning non-existent cache directory
/root/.fontconfig: not cleaning non-existent cache directory
fc-cache: succeeded1. 데이터 수집
import pandas as pd #pandas 사용을 위해 import
import numpy as np #numpy 사용을 위해import
#데이터 불러오기
data_url = "https://covid19.who.int/WHO-COVID-19-global-data.csv" #데이터 링크를 "data_url"에 저장
data = pd.read_csv(data_url) #pandas의 read_csv 메소드를 사용하여 링크로부터 데이터를 가져옴
print(data.head()) #가져온 데이터의 상위 5 lines를 출력
#어떤 날은 칼럼 값 앞에 공백을 붙이고 어떤 날은 공백을 지우고 그래서 위치 별로 칼럼 값 통일
cols = data.columns.tolist()
Date_reported, Country_code, Country, WHO_region, New_cases, Cumulative_cases, New_deaths, Cumulative_deaths = cols[0], cols[1], cols[2], cols[3], cols[4], cols[5], cols[6], cols[7]- 데이터는 who 홈페이지에서 가져왔고 pandas의 read_csv 함수를 사용하여 data 변수에 저장하였다.
- 칼럼 값은 항상 똑같지가 않기 때문에 각 변수에 저장을 하나씩 해주었다.
[출력]
Date_reported Country_code ... New_deaths Cumulative_deaths
0 2020-01-03 AF ... 0 0
1 2020-01-04 AF ... 0 0
2 2020-01-05 AF ... 0 0
3 2020-01-06 AF ... 0 0
4 2020-01-07 AF ... 0 0
[5 rows x 8 columns]
2. Dataframe 생성 및 정제(Cleaning), 전처리(Preprocessing)
#Dataframe 생성
df = pd.DataFrame(data[:])
#이후 월별로 표현하기위해 날짜를 datetime object로 변경
df["datetime"] = df[Date_reported].apply(lambda x: pd.to_datetime(str(x), format="%Y-%m-%d"))
print(df.head())
#index는 "datetime"으로 지정
df.set_index("datetime", inplace=True)
print(df.head())
#WHO_region, Date_reported은 필요없으므로 삭제
df.drop([WHO_region,Date_reported], axis=1, inplace=True)
print(df.head())- 이후에 월별 데이터도 확인하게 위해서 apply 함수를 사용해 "Date_reported"열에 있는 모든 값들을 datetime object로 변경하여 "datetime"열에 저장한다.
- 변환한 datetime열을 index로 지정한다.
- "WHO_region, Date_reported" 두 개의 열은 이후 과정에서 필요없으므로 과감하게 삭제해버린다.
[출력]
Date_reported Country_code ... Cumulative_deaths datetime
0 2020-01-03 AF ... 0 2020-01-03
1 2020-01-04 AF ... 0 2020-01-04
2 2020-01-05 AF ... 0 2020-01-05
3 2020-01-06 AF ... 0 2020-01-06
4 2020-01-07 AF ... 0 2020-01-07
[5 rows x 9 columns]
Date_reported Country_code ... New_deaths Cumulative_deaths
datetime ...
2020-01-03 2020-01-03 AF ... 0 0
2020-01-04 2020-01-04 AF ... 0 0
2020-01-05 2020-01-05 AF ... 0 0
2020-01-06 2020-01-06 AF ... 0 0
2020-01-07 2020-01-07 AF ... 0 0
[5 rows x 8 columns]
Country_code Country ... New_deaths Cumulative_deaths
datetime ...
2020-01-03 AF Afghanistan ... 0 0
2020-01-04 AF Afghanistan ... 0 0
2020-01-05 AF Afghanistan ... 0 0
2020-01-06 AF Afghanistan ... 0 0
2020-01-07 AF Afghanistan ... 0 0
[5 rows x 6 columns]#국가별 데이터 평균
global_data = df.groupby(Country).mean()
global_data.reset_index(level = Country, inplace=True) #국가별 barplot을 그리기위해 "Country"를 Index -> Column으로 변경
print(global_data)
#날짜별 전체 국가의 평균
global_data_mean = df.groupby("datetime").mean()
print(global_data_mean)
#월별 데이터(평균)으로 저장
global_data_mean_monthly = global_data_mean.resample('MS').mean()
print(global_data_mean_monthly)- "global_data"에서는 groupby 함수를 사용하여 "Country"별 평균 값들을 만들어주었으며 "Country"값이 index로 넘어간다. 이후에 시각화를 위해 reset_index 함수를 사용해 index로 들어간 "Country"열을 Column 값으로 넘겨준다.
- "global_data_mean"은 전세계의 날짜별 총확진자, 새확진자, 총사망자, 새사망자들의 평균 값을 계산한 테이블이다.
- "global_data_mean_monthly"는 전세계의 월별로 평균 값을 계산한 테이블이다.
[출력]
Country ... Cumulative_deaths
0 Afghanistan ... 1272.270378
1 Albania ... 693.994036
2 Algeria ... 1583.186879
3 American Samoa ... 0.000000
4 Andorra ... 61.089463
.. ... ... ...
232 Wallis and Futuna ... 0.612326
233 Yemen ... 444.431412
234 Zambia ... 381.896620
235 Zimbabwe ... 436.890656
236 occupied Palestinian territory, including east... ... 879.312127
[237 rows x 5 columns]
New_cases Cumulative_cases New_deaths Cumulative_deaths
datetime
2020-01-03 0.000000 0.000000 0.000000 0.000000
2020-01-04 0.004219 0.004219 0.000000 0.000000
2020-01-05 0.000000 0.004219 0.000000 0.000000
2020-01-06 0.012658 0.016878 0.000000 0.000000
2020-01-07 0.000000 0.016878 0.000000 0.000000
... ... ... ... ...
2021-05-15 2913.421941 681573.877637 54.932489 14145.059072
2021-05-16 2831.704641 684405.582278 51.835443 14196.894515
2021-05-17 2536.738397 686942.320675 47.421941 14244.316456
2021-05-18 2185.869198 689128.189873 46.683544 14291.000000
2021-05-19 2305.957806 691434.147679 47.827004 14338.827004
[503 rows x 4 columns]
New_cases Cumulative_cases New_deaths Cumulative_deaths
datetime
2020-01-01 1.439837 5.505602 0.030991 0.132548
2020-02-01 10.982249 237.891314 0.396042 6.816674
2020-03-01 96.905676 1147.518035 4.983667 49.817477
2020-04-01 325.219972 8386.996624 26.260197 570.541350
2020-05-01 386.283381 18981.058255 19.389002 1279.339594
2020-06-01 597.768776 33614.741350 18.975949 1840.885795
2020-07-01 948.587178 57243.275487 22.625970 2468.207568
2020-08-01 1123.713352 90364.567442 24.592215 3225.335783
2020-09-01 1215.906329 125789.487482 22.538397 3944.834880
2020-10-01 1665.909487 167931.437730 24.922553 4653.874234
2020-11-01 2429.365260 232318.779325 38.607314 5597.365401
2020-12-01 2592.771063 309958.155301 46.930584 6942.549612
2021-01-01 2691.435960 393432.942698 56.761671 8519.956989
2021-02-01 1681.503767 457236.595389 45.639693 10113.355937
2021-03-01 1956.073908 508085.522254 36.563495 11258.613992
2021-04-01 3126.553727 585423.497468 50.405626 12565.309001
2021-05-01 3043.963136 665824.506107 52.898068 13874.295359#나라별 코드를 사용하여 데이터 조회
def global_data_search(country_code : str):
for name, group in df.groupby(Country_code):
if name == country_code:
#Country_code와 Country는 필요없기때문에 제외
country_data = df[df[Country_code]==name].iloc[:, 2:]
return country_data- 해당 함수는 "country_code"를 받아서 해당 코드에 맞는 나라의 데이터를 조회한다.
#한국 데이터만 조회
korea_data = global_data_search("KR")
korea_data- 위 함수 "global_data_search"를 사용하여 한국의 데이터를 조회해보았다.
[출력]
New_cases Cumulative_cases New_deaths Cumulative_deaths
datetime
2020-01-03 0 0 0 0
2020-01-04 0 0 0 0
2020-01-05 0 0 0 0
2020-01-06 0 0 0 0
2020-01-07 0 0 0 0
... ... ... ... ...
2021-05-15 681 131060 3 1896
2021-05-16 610 131670 4 1900
2021-05-17 619 132289 3 1903
2021-05-18 528 132817 1 1904
2021-05-19 654 133471 8 1912
503 rows × 4 columns#월별 데이터로 변경&저장
korea_data_monthly = korea_data.resample('MS').sum()
korea_data_monthly- 한국 데이터를 월별로 합계를 계산하여 저장해놓은다. 이후에 월별로도 시각화를 할 것이기 때문이다.
[출력]
New_cases Cumulative_cases New_deaths Cumulative_deaths
datetime
2020-01-01 11 54 0 0
2020-02-01 2920 10994 16 75
2020-03-01 6855 242673 146 2590
2020-04-01 979 315359 85 6525
2020-05-01 703 342230 23 8081
2020-06-01 1331 364450 12 8326
2020-07-01 1506 421928 19 9038
2020-08-01 5642 499603 23 9534
2020-09-01 3865 669463 89 10989
2020-10-01 2699 777675 51 13660
2020-11-01 7688 879850 62 14823
2020-12-01 26523 1435786 374 20310
2021-01-01 17476 2203630 520 37480
2021-02-01 11467 2352317 183 42502
2021-03-01 13415 2989247 128 51888
2021-04-01 18927 3376051 97 53527
2021-05-01 11464 2430722 84 35572#결측치 확인
print("일별 데이터\n", korea_data.isnull().sum())
print("월별 데이터\n", korea_data_monthly.isnull().sum())- "korea_data", "korea_data_monthly" 각각에 null값이 있는지 없는지 확인한다.
[출력]
일별 데이터
New_cases 0
Cumulative_cases 0
New_deaths 0
Cumulative_deaths 0
dtype: int64
월별 데이터
New_cases 0
Cumulative_cases 0
New_deaths 0
Cumulative_deaths 0
dtype: int643. 기초 통계 분석
New_cases = 새로운 감염자 수, Cumulative_cases = 전체 감염자 수, New_deaths = 새로운 사망자 수, Cumulative_deaths = 전체 사망자 수
#Summary
korea_data.describe()- describe 함수를 사용하면 count, mean, std, min 등을 종합적으로 보여준다.
[출력]
New_cases Cumulative_cases New_deaths Cumulative_deaths
count 503.000000 503.000000 503.000000 503.000000
mean 265.349901 38393.701789 3.801193 645.964215
std 278.727689 38677.989386 5.395165 619.418754
min -4.000000 0.000000 0.000000 0.000000
25% 39.000000 10816.000000 0.000000 256.000000
50% 124.000000 21743.000000 2.000000 346.000000
75% 456.000000 70455.000000 5.000000 1190.000000
max 1235.000000 133471.000000 40.000000 1912.000000#평균
korea_data.mean(axis=0)- mean 함수를 사용하면 평균값을 계산하여 보여준다. axis = 0이면 row를 기준으로 계산해준다.
[출력]
New_cases 265.349901
Cumulative_cases 38393.701789
New_deaths 3.801193
Cumulative_deaths 645.964215
dtype: float64#최댓값, 최소값
print("MAX : \n", korea_data.max())
print("MIN : \n", korea_data.min())- max, min 함수는 각각 최댓값과 최소값을 계산하여 보여준다.
[출력]
MAX :
New_cases 1235
Cumulative_cases 133471
New_deaths 40
Cumulative_deaths 1912
dtype: int64
MIN :
New_cases -4
Cumulative_cases 0
New_deaths 0
Cumulative_deaths 0
dtype: int64#합계
korea_data.sum(axis=0)- sum 함수는 합계를 계산하여 보여준다. axis=0은 row기준을 말한다.
[출력]
New_cases 133471
Cumulative_cases 19312032
New_deaths 1912
Cumulative_deaths 324920
dtype: int64#표준편차
korea_data.std(axis=0)- std 함수는 표준편차를 계산하여 보여준다. axis=0은 row기준을 말한다.
[출력]
New_cases 278.727689
Cumulative_cases 38677.989386
New_deaths 5.395165
Cumulative_deaths 619.418754
dtype: float644. 데이터 시각화
import seaborn as sns #시각화 모듈 seaborn import
import matplotlib #시각화 모듈 matplotlib import
import matplotlib.pyplot as plt #시각화 설정을 위해 matplotlib.pyplot import
#그래프의 major, minor 틱(tick)을 각각 월별, 일별로 위치시키고 Date 형식으로 Format하기 위해
#matplotlib.dates에 있는 DateFormatter, DayLocator, MonthLocator import
from matplotlib.dates import DateFormatter, DayLocator, MonthLocator
#폰트를 나눔고딕체로 설정
plt.rc('font', family='NanumBarunGothic')
#Figure Set
fig, ((ax_lst1, ax_lst2), (ax_lst3, ax_lst4)) = plt.subplots(2,2,figsize=(20, 15))
#한국 일별 그래프
ax_lst1.set_title("새 감염자 수")
ax_lst2.set_title("총 감염자 수")
ax_lst3.set_title("새 사망자 수")
ax_lst4.set_title("총 사망자 수")
sns.lineplot(x="datetime", y=New_cases, data=korea_data, ax = ax_lst1)
sns.lineplot(x="datetime", y=Cumulative_cases, data=korea_data, ax = ax_lst2)
sns.lineplot(x="datetime", y=New_deaths, data=korea_data, ax = ax_lst3)
sns.lineplot(x="datetime", y=Cumulative_deaths, data=korea_data, ax = ax_lst4)- 맨 처음 설치한 한글 폰트를 matplot.rc의 'font' 속성을 지정하여 넣어준다.
- 그래프들의 배치를 어떻게 할지 정하기 위해 subplots로 몇행 몇열인지 지정해주고 figsize로 전체 사이즈를 지정해준다. 각 배치들은 "((ax_lst1, ax_lst2), (ax_lst3, ax_lst4))"와 같이 튜플형식으로 지정해줄 수 있다.
- 각 배치들의 title은 set_title 함수를 사용해 지정해준다.
- 시각화 모듈은 seaborn을 사용하였고 seaborn의 lineplot을 사용하여 각 column 별로 그래프를 생성한다. 배치 위치는 ax 속성에 지정해준다.
[출력]

#폰트를 나눔고딕체로 설정
plt.rc('font', family='NanumBarunGothic')
#Figure Set
fig, ((ax_lst1), (ax_lst2)) = plt.subplots(2,1,figsize=(15, 15))
#국가별 데이터 내림차순 정렬
global_data.sort_values(New_cases, ascending=False, inplace=True)
sns.set_color_codes("pastel")
#상위 30개의 국가 출력
ax_lst1.set_title("상위 30위")
sns.barplot(x=New_cases, y=Country, data=global_data.head(30), ax=ax_lst1)
#하위 30개의 국가 출력
ax_lst2.set_title("하위 30위")
sns.barplot(x=New_cases, y=Country, data=global_data.tail(30), ax=ax_lst2)- 이번에 상위 30위 국가들과 하위 30위 국가들을 확인하기위해서 우선 sort_values함수를 사용하여 내림차순 정렬을 한다. 이때 ascending값을 True로 지정하면 오름차순이 된다.
- 그래프는 barplot으로 지정해주었고 head와 tail 함수를 사용해 각각 상위 30위, 하위 30위 국가들을 나타내주었다.
[출력]

#세계 일별 데이터 평균
#폰트를 나눔고딕체로 설정
plt.rc('font', family='NanumBarunGothic')
#Figure Set
fig, ((ax_lst1, ax_lst2), (ax_lst3, ax_lst4)) = plt.subplots(2,2,figsize=(20, 15))
ax_lst1.set_title("새 감염자 수")
ax_lst2.set_title("총 감염자 수")
ax_lst3.set_title("새 사망자 수")
ax_lst4.set_title("총 사망자 수")
sns.scatterplot(x="datetime", y=New_cases, data=global_data_mean, ax=ax_lst1)
sns.scatterplot(x="datetime", y=Cumulative_cases, data=global_data_mean, ax=ax_lst2)
sns.scatterplot(x="datetime", y=New_deaths, data=global_data_mean, ax=ax_lst3)
sns.scatterplot(x="datetime", y=Cumulative_deaths, data=global_data_mean, ax=ax_lst4)- 이번엔 scatterplot으로 전세계 평균 값을 시각화하여 나타내보았다.
[출력]
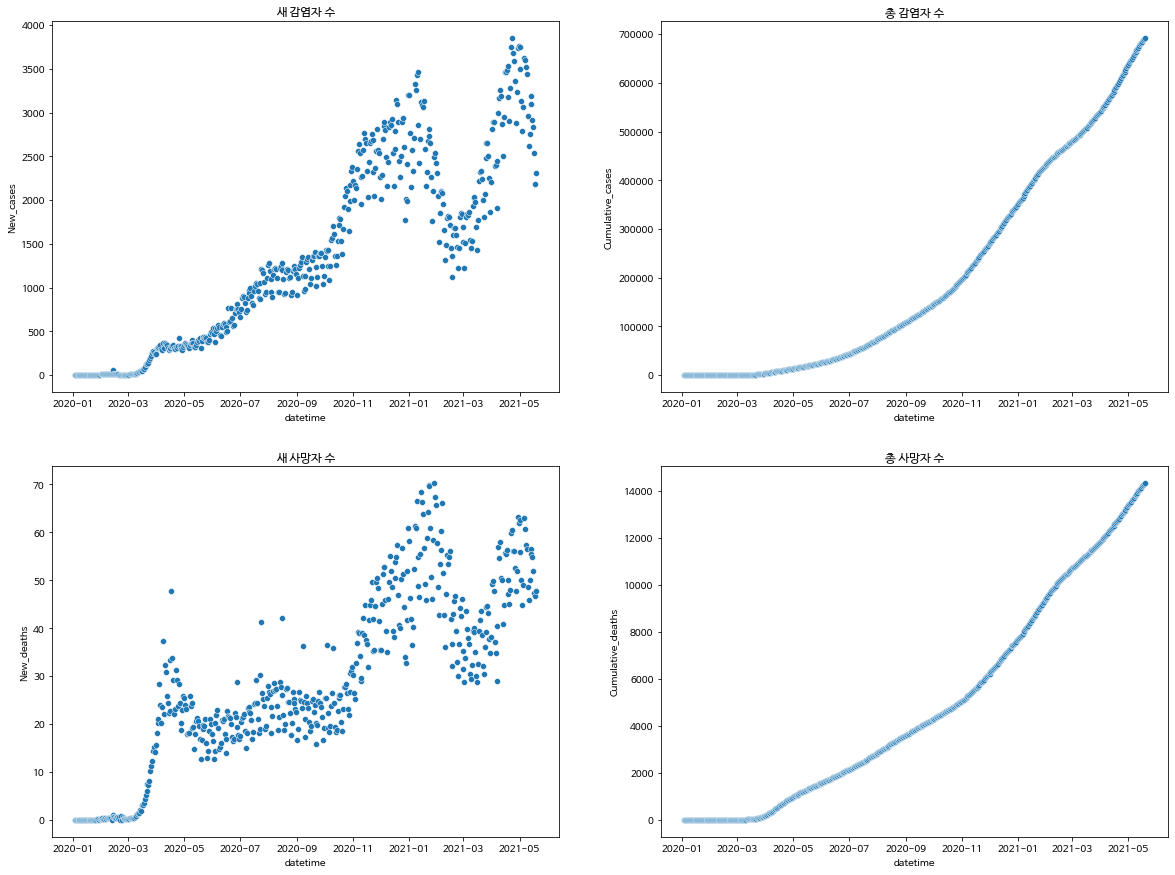
#세계 일별 평균과 한국 일별 평균과의 그래프 비교
#폰트를 나눔고딕체로 설정
plt.rc('font', family='NanumBarunGothic')
#Figure Set
fig, ((ax_lst1), (ax_lst2),(ax_lst3),(ax_lst4)) = plt.subplots(4, 1, figsize=(35, 40))
#눈금(tick) 표현을 위해 그리드 제거
plt.grid(False)
plt.tick_params(axis="x", which = "major", length=10, color="gray") #큰 눈금 설정
plt.tick_params(axis="x", which='minor', length=5, color='gray') #작은 눈금 설정
#title 설정
ax_lst1.set_title("세계 일별 평균과 한국 일별 평균과의 그래프 비교(새 감염자 수)")
ax_lst2.set_title("세계 일별 평균과 한국 일별 평균과의 그래프 비교(총 감염자 수)")
ax_lst3.set_title("세계 일별 평균과 한국 일별 평균과의 그래프 비교(새 사망자 수)")
ax_lst4.set_title("세계 일별 평균과 한국 일별 평균과의 그래프 비교(총 사망자 수)")
#각 axes의 일별, 월별 눈금 위치 설정
for i in [ax_lst1, ax_lst2, ax_lst3, ax_lst4]:
i.xaxis.tick_bottom()
i.xaxis.set_major_locator(MonthLocator()) #큰 눈금을 월별로 위치 설정
i.xaxis.set_major_formatter(DateFormatter('%Y-%m')) #큰 눈금의 tick label을 년-월 형식으로 Format
i.xaxis.set_minor_locator(DayLocator()) #작은 눈금을 일별로 위치 설정
#한국과 세계 평균을 비교하기위해 각 axes에 둘 다 지정
sns.lineplot(x = "datetime", y = New_cases, data=korea_data, ax = ax_lst1)
sns.lineplot(x = "datetime", y = New_cases, data=global_data_mean, ax = ax_lst1)
sns.lineplot(x = "datetime", y = Cumulative_cases, data=korea_data, ax = ax_lst2)
sns.lineplot(x = "datetime", y = Cumulative_cases, data=global_data_mean, ax = ax_lst2)
sns.lineplot(x = "datetime", y = New_deaths, data=korea_data, ax = ax_lst3)
sns.lineplot(x = "datetime", y = New_deaths, data=global_data_mean, ax = ax_lst3)
sns.lineplot(x = "datetime", y = Cumulative_deaths, data=korea_data, ax = ax_lst4)
sns.lineplot(x = "datetime", y = Cumulative_deaths, data=global_data_mean, ax = ax_lst4)- 세계 평균 값과 한국 평균 값을 비교하면 어떨까 궁금해서 한 번 시각화를 해보았다.
- 이번에는 tick_params 함수를 사용하여 작은 눈금과 큰 눈금을 직접 설정해주었다.
- major는 큰 눈금, minor는 작은 눈금을 가리키는데 tick_bottom함수로 맨 아래에 표시되도록 하였고 set_major_locator로 큰 눈금은 월(month), set_minor_locator로 작은 눈금은 일(day)를 가리켰다. 그리고 set_major_formatter함수를 사용하여 "년-월" 문자가 나타나도록 formatting 해주었다.
[출력]
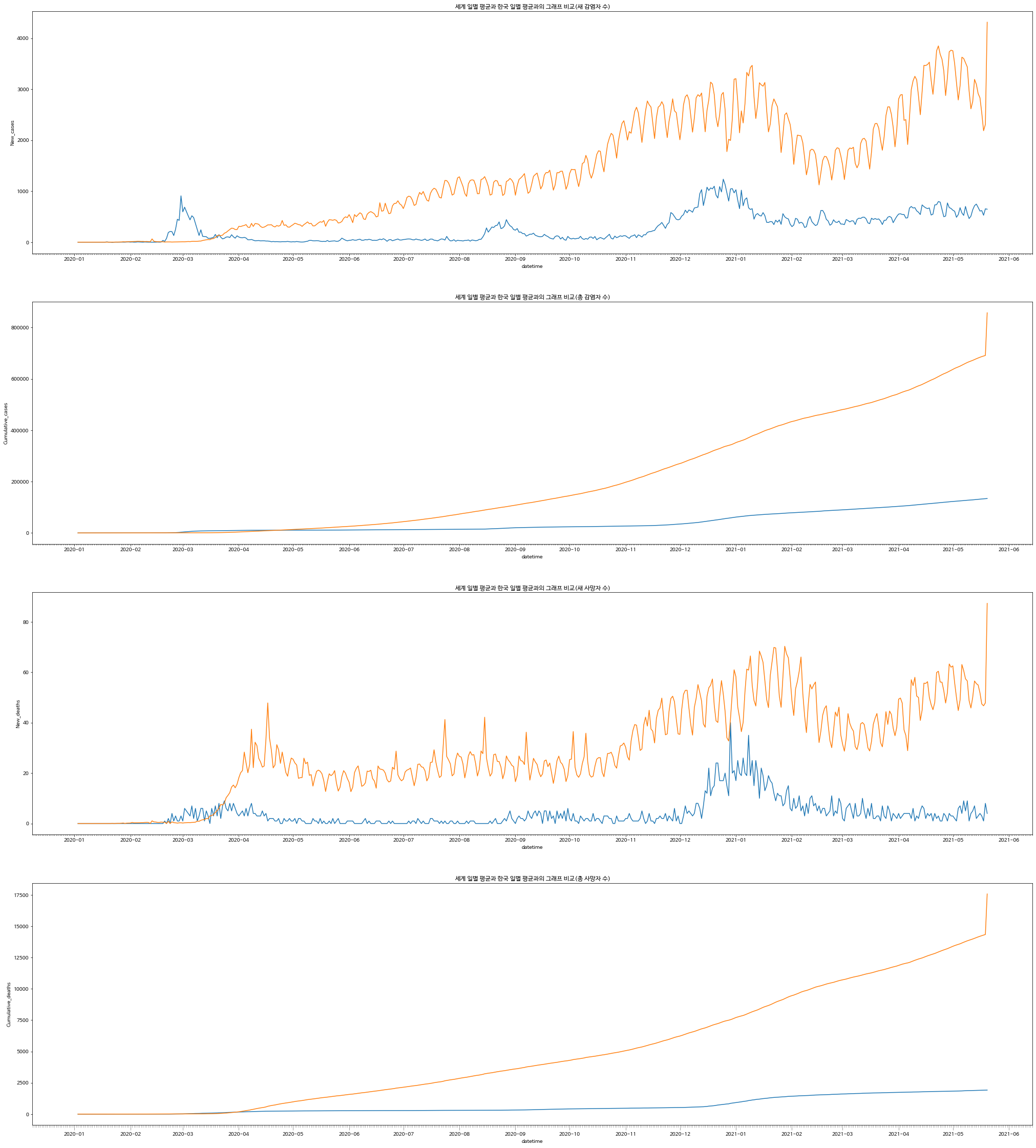
#1. 새 사망자 수, 새 감염자 수의 히스토그램
#2. 새 감염자 수에 대한 새 사망자 수를 hex형태로 표현
sns.set_theme(style="darkgrid")
k = sns.jointplot(x=New_cases, y=New_deaths, data=korea_data, kind="hex")
g = sns.jointplot(x=New_cases, y=New_deaths, data=global_data_mean, kind="hex")
k.fig.suptitle("Korea")
g.fig.suptitle("Global")- 이번엔 그냥 joinplot을 사용하여 "hex" 형식으로 아무 의미없이 표현해보았다. 새 사망자수와 새 확진자수의 분포도를 확인할 수 있는 히스토그램이라고 할 수 있다.
[출력]

COVID-19
Colaboratory notebook
colab.research.google.com
728x90
'Machine Learning > Coding' 카테고리의 다른 글
| [실습]Bernoulli Naive Bayes(베르누이 나이브 베이즈) (0) | 2021.06.10 |
|---|---|
| [실습] Gaussian Naive Bayes(가우시안 나이브 베이즈) (0) | 2021.06.07 |
| [실습]의사결정 트리(Decision Tree) (3) | 2021.06.01 |
| [실습]SVM(Support Vector Machine) (2) | 2021.05.27 |
| [실습] k-최근접 이웃(k-Nearest Neighbor, kNN) (0) | 2021.05.22 |