CNN visualization
- CNN이 패턴을 발견해 내는 과정을 시각화하여 확인하는 방법
- CNN을 visualization한다는 것은 debugging tool을 갖는다는 것과 같다.
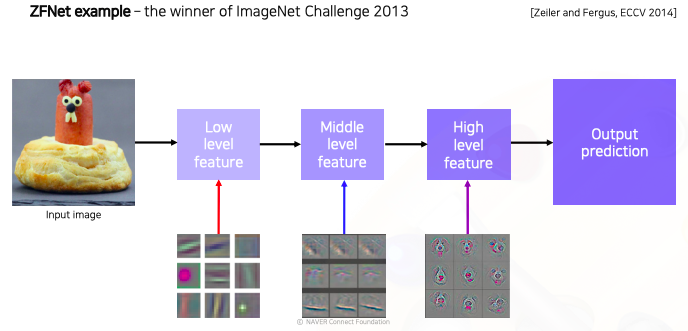
low level에는 좀 더 방향성이 있는 선을 찾는 필터들처럼 기본적인 영상처리 필터들같이 생긴 것들이 보이고 high level로 갈수록 점점 의미있는 표현을 학습한다. 이렇게 눈으로 보면서 튜닝을 하는 ZFNet이라는 것을 제한하였고 2013년 ImageNet Challenge에서 우승하였다.
- filter visualization
AlexNet에서 다음과 같이 11 x 11 x 3 크기인 filter size를 첫 번째 convolutional layer에 사용한다면 각종 영상처리 필터(color edge detector, angle detector, block detector 등)로 학습되었다는 것을 알 수 있다. 이를 Activation visualization을 한다면 각 필터마다 한 채널로 나오기 때문에 흑백으로 나오지만 각 필터의 특성마다의 detail한 결과를 볼 수 있다.

첫 번째 layer의 경우 3개의 채널로 구성되어 visualization을 할 수 있지만 뒤쪽 레이어는 차원 수가 높기 때문에 visualization을 하는데 어려움이 있다.
- Types of neural network visualization
model에 중점을 둔(model을 이해하기위한) 유형과 data에 중점을 둔(data를 분석하기 위한) 유형으로 나눌 수 있다.

Embedding feature analysis
high level에서 나오는 feature들을 분석하는 방법
- Nearest neighbors (NN)
아래 그림처럼 코끼리의 경우 의미론적인 비슷한 concept을 잘 clustering되었다는 것을 알 수 있다. 다음으로 개 사진이 주어졌을 때 pixel 별로 비교하여 검색이 될 수 있다. 이 때 위치가 다르거나 다른 포즈를 취한 개도 검색이 되는데 이는 object의 위치 변화에 굉장히 강인하게 concept를 잘 학습했다고 볼 수 있다.

- Dimensionality reduction

고차원 공간의 경우 해석의 어려움이 있기때문에 저차원 공간으로 축소함으로서 눈으로 확인하기 쉽게할 수 있다.
1. t-distributed stochastic neighbor embedding (t-SNE)

- Layer activation
mid level과 high level을 해석하는 것으로 layer의 activation을 분석함으로서 model의 특성을 파악하는 방법이다.

- Maximally activating patches
layer activation을 분석하는 비슷한 방법 중에 patch를 뜯어서 사용하는 방법이 있다. 각 레이어의 채널에서 하는 역할을 판단하기 위해 hidden node에서 가장 큰 값을 가져온다고 했을 때 다음과 같이 얻을 수 있을 것이다. 그리고 mid level에서 사용하기 적합하다.

구현하는 방법은 다음과 같다.
a. 분석하고자하는 특성 layer에서 channel을 선택한다. 예를 들어서 convolution 5 layer에서 256개의 channel 중 14개의 channel을 고를 수 있다.

b. 각 예제 이미지들을 feeding하고 얻고자하는 각 channel에서 activation value를 저장한다.
c. 저장된 해당 channel에 activation 값들 중에 가장 큰 값을 갖는 위치를 파악하고 그 위치를 파악하면 input의 receptive field에 해당하는 patch를 뜯어온다.
- Class visualization
각 class를 판단할때 이 network는 어떤 모습을 상상하고 있을까라는 것을 확인할 수 있다. 다음과 같이 해당 class의 object만 판단하는 것이 아닌 그 주위의 것들도 같이 찾는다라는 것을 알 수 있다.

이런 영상은 어떻게 추출하는 것인지 알아보면 gradient descent와 같은 최적화를 하게되는데 이와 반대인 gradient ascent를 사용한다.
다음과 같이 두 가지 loss를 합성해서 쓰는데 우선 첫 번째는 어떤 입력이 주어졌을 때 어떤 CNN model f()를 거쳐 출력된 하나의 class score를 maximize하는 것이고 두 번째는 영상이 아닌 객체들도 찾게 될 때 우리가 알고 있는 또는 이해할 수 있는 영상을 유도하기 위해 추가한 것이다. 또한 L2 norm의 합이 작아지는 방향으로 람다 값을 사용하여 컨트롤한다.

a. 임의의 영상으로 분석하고자하는 CNN에 입력 값으로 넣어준다.

b. backpropagation을 통해서 입력단의 gradient를 구한다. 즉, 입력이 어떻게 변해야지 target class의 score가 커지는지를 찾는 것이다. 반대로 target class score에 -를 붙이고 minimize하는 방향으로 학습시킨다고 한다면 이전에 사용하던 gradient descent를 적용하면된다.

c. 현재 이미지를 update(이후 반복)

Model decision explanation
- Saliency test
영상이 주어졌을 때 제대로 판정되기 위한 각 영역의 중요도를 추천하는 방법
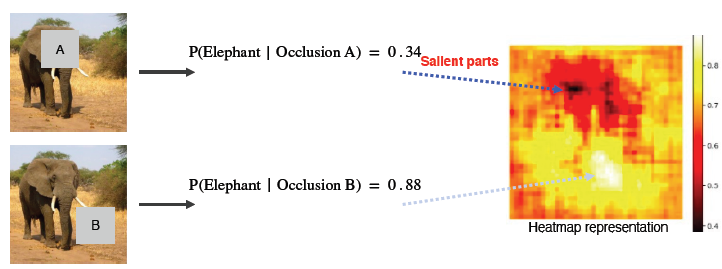
- Occlusion map
다음의 윗 그림에서 A라는 Occlusion을 가렸을 때의 코끼리를 입력으로 주어졌을 때의 확률이고 아래 그림은 B라는 Occlusion을 가렸을 때의 코끼리를 입력으로 주어졌을 때의 확률을 구한 것이다. 이처럼 어떤 부분을 가려주느냐에 따라 확률이 상당히 다르다는 것을 알 수 있다.
오른쪽의 heatmap은 Occlusion 위치에 따라 변하는 score를 나타낸 것이다. 색을 비교해보면 검은색에 가까울 수록 그 부분은 중요하다고 볼 수 있고 흰색에 가까울 수록 중요하지 않은 부분이라고 할 수 있을 것이다.
- via Backpropagation
Backpropagation을 사용하여 특정 이미지를 classification을 해보고 최종 결론이 나온 class에 결정적으로 영향이 미친 곳이 어디인지를 heatmap으로 나타낸 방법이다.

a. 입력 영상을 넣고 하나의 class score를 얻는다.
b. 입력 도메인까지의 Backpropagation을 통해 gradient 값을 얻고 절대값을 취하거나 제곱을 해준다. 여기서 절대값을 취하거나 제곱을 해주는 이유는 gradient의 크기 자체가 입력에서 많이 바뀌어야 score가 바뀐다는 것을 의미하기 때문이다.
c. 이전 단계에서 얻은 gradient map을 시각화한다. 즉, input에서 어떠한 부분이 민감한지를 나타내는 것이다.
이전의 Class visualization에서와 달리 input에 따라 dependent한 해석하는 방법이므로 input에 따라 달라진다.
Backpropagation-based saliency
- Rectified unit (backward pass)
일반적으로 CNN에서 ReLU가 많이 사용되는데 아래처럼 Forward pass에서 음수가 나오는 부분은 0으로 마스킹된다. 그리고 backpropagation할 때 양수와 음수가 합쳐진 gradient가 오면 음수 마스크로 저장되어있던 패턴 마스크로 마스킹을 해준다. 하지만 Zeiler는 deconvolution을 사용하여 backward pass때도 음수에 해당하는 부분을 마스킹하는 방법을 사용하였다고 한다. 즉, backward에도 ReLU 함수를 사용을 했다고 할 수 있다.

수식으로 표현하면 다음과 같다.

더 나아가서 다음과 같이 두 가지 방법을 and gate하는 방법도 있다고 한다.

결과는 다음과 같이 나오는 것을 보면 두 가지 방법을 and gate한 것이 좀 더 clean한 결과를 얻을 수 있다.

Class activation mapping
- CAM
가장 많이 사용하는 visualization algorithm이다. CAM은 어떤 부분을 참조하여 어떤 결과가 나왔는지 heatmap과 같은 형태로 표현해준다.

CAM은 neural network의 일부를 조금 개조를 해야한다. 다음과 같이 convolution의 마지막 feature map을 gap을 적용시키고 그 다음 fc layer를 하나만 통과시켜 최종적으로 classification하게 만들어준다.

예를 들어 하나의 클래스 c에 대한 score(s)는 마지막 fc layer의 weight들과 gap feature, 각 공간축의 평균값을 내서 하나의 노드로 만든 그런 layer의 feature들의 linear combination으로 score가 만들어졌다.



위 결과처럼 위치정보가 주어지지 않아도 위치를 파악하는 장점이 있다.
다만 CAM 적용이 가능한 제약으로는 마지막 레이어 구성이 gap과 fc layer로 구성되어야한다는 단점이 있다.

- Grad-CAM
구조 변경이 필요없이 CAM을 사용할 수 있는 Grad-CAM이 개발되었다.

기존 pre-train된 model을 변경하지 않고 구할 수 있기 때문에 꼭 영상인식 task에 국한 될 필요가 없다. 즉, backbone이 CNN이기만 하면 사용할 수 있다.

이전에는 입력 영상까지 backpropagation을 했지만 이번에는 관심을 가지고 있는 activation map까지만 backpropagation한다. 현재 task에서 해석하고 싶은 결과 y(class score), y를 변화시키는 loss 로부터 gradient를 구하게 되고 gap을 하여 공간축으로 average pooling을 적용하게 되는 것이다. 그래서 각 channel의 gradient 성분을 구하게 된다.
그리고 이것을 선형결합을 통해서 결합을 해주는데 이전과는 다르게 ReLU를 사용하여 양수 값만 사용한다.

Further Question
1. 왜 filter visualization에서 주로 첫 번째 convolutional layer를 목표로 할까?
-> 첫 번째 layer의 경우 3개의 채널로 구성되어 visualization을 할 수 있지만 뒤쪽 레이어는 차원 수가 높기 때문에 visualization을 하는데 어려움이 있다.
2. Occlusion map에서 heatmap이 의미하는 바가 무엇일까?
-> heatmap은 Occlusion 위치에 따라 변하는 score를 나타낸 것이다. 색을 비교해보면 검은색에 가까울 수록 그 부분은 중요하다고 볼 수 있고 흰색에 가까울 수록 중요하지 않은 부분이라고 할 수 있을 것이다.
3. Grad-CAM에서 linear combination의 결과를 ReLU layer를 거치는 이유가 무엇인가?
-> 양수 값만 사용하기 위해서