Object detection
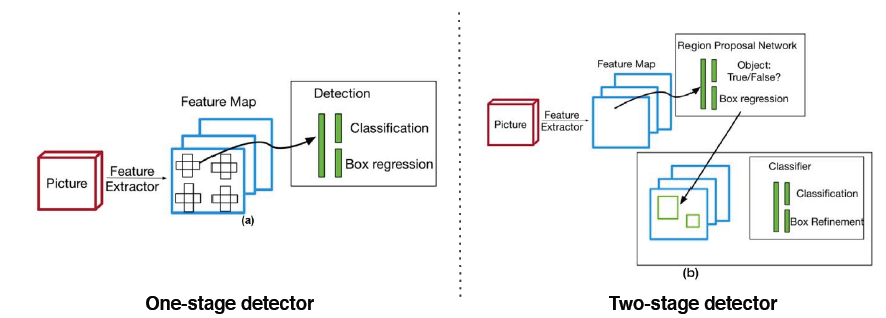
1. Two-stage detector
- Gradient-based detector(e.g., HOG)(2005)
경계선의 특징을 잘 모델링하기위한 엔지니어링을 수행했다. 간단한 선형 모델인 SVM을 사용

- Selective search(2013)
bounding box를 제한해서 추출해주는 방법이다.
- 우선 아래 그림의 맨 왼쪽처럼 잘게 분할을 해주는데 이것을 Over-segmentation이라 부른다.
- 비슷한 영역끼리 반복적으로 합친다.
- 반복적으로 합친 큰 segmentation이 나오는데 이런 segmentation이 포함된 bounding box를 후보로 추출해준다.
- R-CNN(2014)
- selective search를 사용하여 region proposal들을 extract한다.
- extract된 region은 warp되어 CNN 연산이 수행된다.
- classifier는 간단하고 고전적인 모델인 SVM을 사용한다.
- Fast R-CNN(2015)
- Selective Search를 통해 RoI를 찾는다.
- 전체 이미지를 CNN에 수행시켜 feature map을 추출
- Selective Search으로 찾은 RoI를 feature map 크기에 맞춰 projection
- projection된 RoI에대해 RoI Pooling을 적용시켜 고정된 크기의 feature vector를 얻는다.
- 얻은 feature vector는 FC Layer를 통과 후 두 개의 branch로 나뉜다.
- 한 쪽은 softmax를 통해 classification을 수행하고 다른 한 쪽은 bounding box regression을 통해 Selective Search로 찾은 box의 위치를 조정한다.
- Faster R-CNN
- IoU(Intersection over Union) : 두 영역의 ovelap을 측정하는 기준
- Anchor boxes : 미리 정의된 bounding box를 의미하며 IoU에 따라 positive sample인지 negative sample인지 판단할 수 있다. 예를 들어 IoU가 0.7보다 크면 positive, 0.3보다 작으면 negative라고 할 수 있다.
- 이전 Fast R-CNN까지 Selective search를 사용하여 region을 추출했지만 Faster R-CNN에서는 Region Proposal Network(RPN)을 사용하여 region을 추출한다.
- feature map위에 N x N 크기의 Window를 받아 해당 영역에 어떤 물체(object)가 있는지 없는지를 classification layer(cls layer)와 bounding box의 4개 좌표 (x,y,w,h)를 결정하는 bounding box regression(reg layer)으로 구성된다.
5. Non-Maximum Suppression (NMS)
- 가장 높은 점수를 받은 bounding box를 선택
- 다른 box들과의 IoU를 비교
- IoU가 50%이상인 bounding box는 삭제
- 다음으로 높은 점수로 이동
- 반복 수행
- Summary of the R-CNN family
2. Single-stage detector
빠른 속도와 간단한 구조를 가진다.
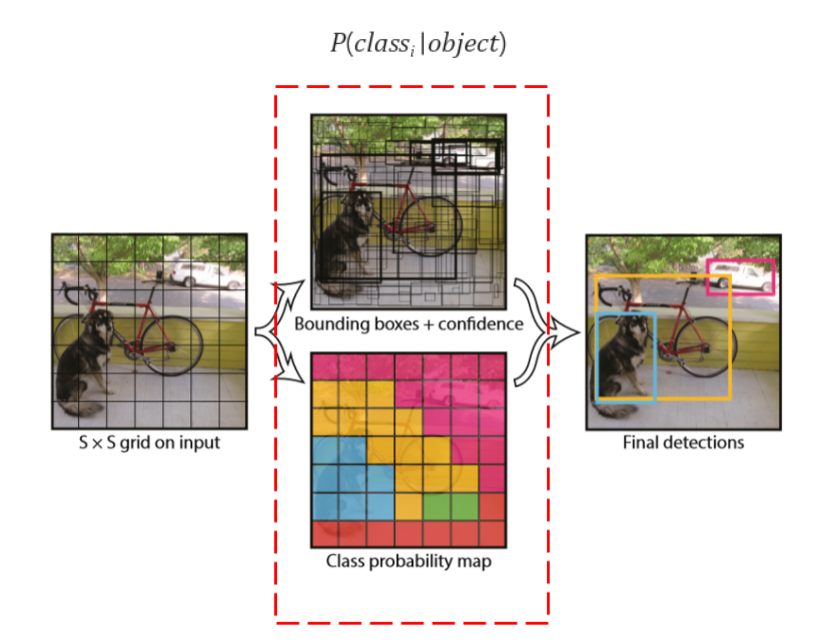
- You only look once(YOLO)
좀 더 자세히 살펴보면 가운데 위쪽은 BBox에 대한 정보를 나타내는 것이고 서로 다른 크기의 많은 BBox가 그려져있다. 위에서 처럼 그리드를 7x7로 나누고 각 그리드 셀에서 크기가 일정하지 않은 BBox를 2개씩 생성한다고하자. 그러면 그리드 셀이 총 49개이므로 BBox는 98개가 만들어진다. 이 중 BBox 안에 어떤 object가 있을 것 같다고 확신(confidence scrore)할수록 BBox 테두리를 굵게 그려진다. 따라서 BBox의 위치정보와 confidence score의 정보를 포함하고 있다고 말할 수 있다.
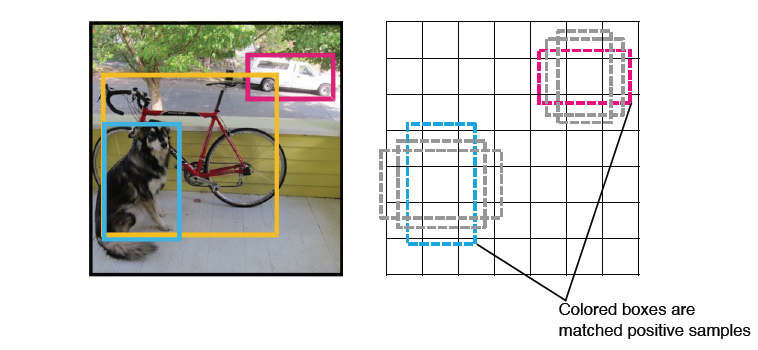
Fast R-CNN과 같은 방식으로 positive sample을 구별한다.
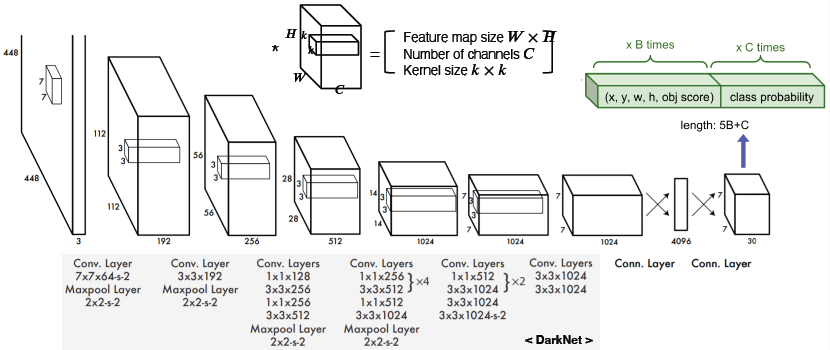
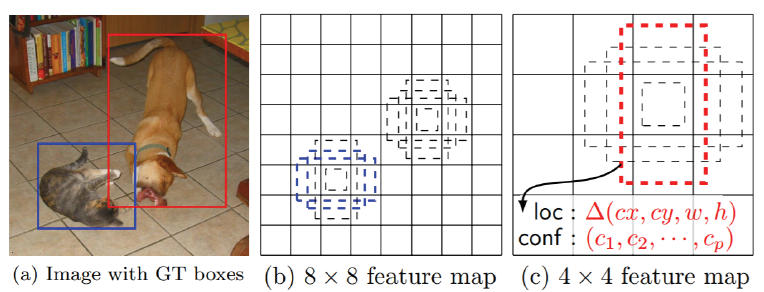
- Single Shot MultiBox Detector (SSD)
YOLO의 경우 맨 마지막 레이어에서만 prediction을 하기 때문에 localization 정확도가 떨어진다. 이러한 점을 보완하기 위해 SSD라는 방법이 나왔다.
SSD는 multi scale object를 잘 처리하게 위해서 중간 feature map을 각 해상도에 적절한 bounding box를 출력할 수 있도록 하였다.
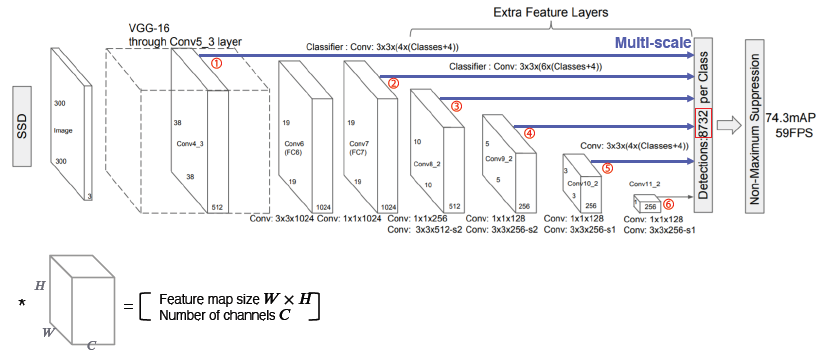
YOLO보다 더 빠르고 정확한 성능을 가진다.
3. Two-stage detector vs. one-stage detector
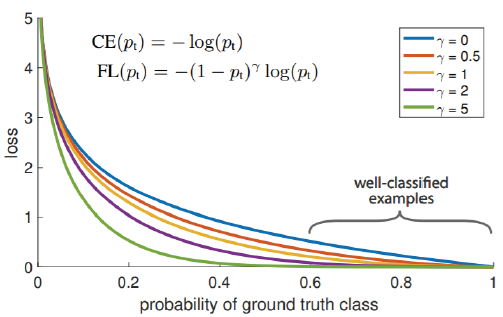
- Focal loss
one-stage detector의 경우 RoI pooling이 없기 때문에 모든 영역에서의 loss가 계산된다. positive sample은 적은데 negative sample은 많이 가지기 때문에 Class Imbalance 문제가 발생하게 된다.
이런 문제를 해결하기위해 Focal loss를 사용한다.
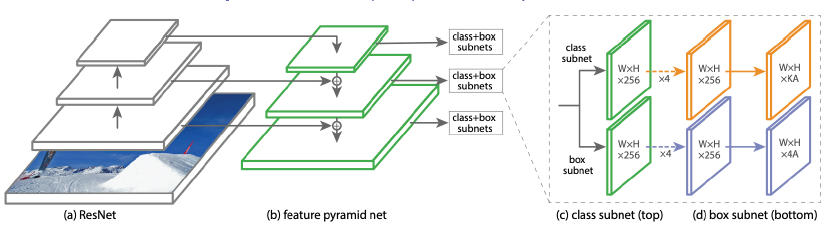
- RetinaNet
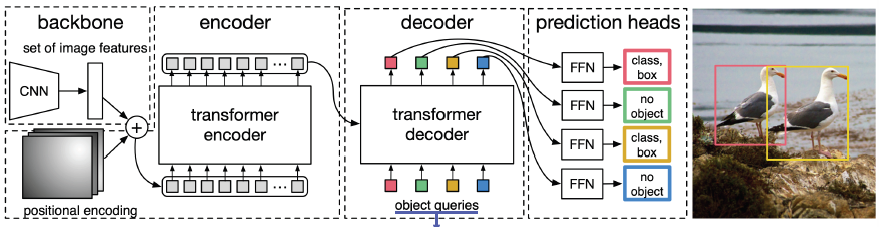
4. DETR(Detection Transformer)
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp Day-30] Computer Vision - CNN Visualization (0) | 2021.09.14 |
|---|---|
| Fully Convolutional Networks(FCN) and VGGNet Segmentation Implemenation (0) | 2021.09.12 |
| Deconvolution and Checkerboard Artifacts (0) | 2021.09.10 |
| [Boostcamp Day-28] Computer Vision - Semantic Segmentation (0) | 2021.09.09 |
| [Boostcamp 6주차] 피어세션과 학습 회고 (0) | 2021.09.09 |