Instance segmentation
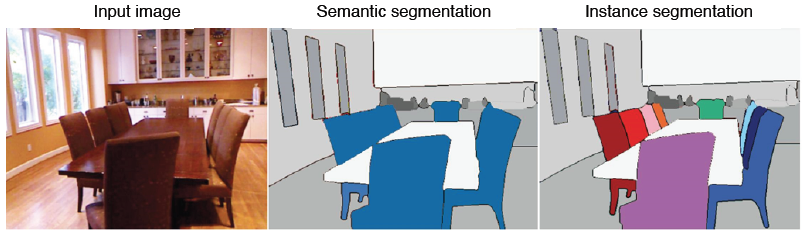
instance segmentation은 위 그림처럼 같은 클래스라도 instance가 다르면 구분을 해준다.
- Mask R-CNN
Fast R-CNN에서는 RPN(region proposal network)에 의해 나온 bounding box에 RoI Pooling을 사용하였다. 그리고 기존 RoI Pooling은 정수 좌표밖에 지원하였다. 하지만 Mask R-CNN에서는 RoIAlign이라는 새로운 Pooling layer를 제안하였고 RoIAlign에서는 interpolation을 통해서 소수점 픽셀 level의 pooling을 지원하게 되었다. 따라서 더욱 정교한 feature를 뽑을 수 있게 되고 그 뒷단의 성능이 향상되는 것으로 이어진다.

그리고 Fast R-CNN에서는 pooling된 feature 위에 올라가있던 Classifiaction과 box regression이 있었다. Mask R-CNN에서는 좀 더 확대해서보면 Mask branch가 있는데 아래 그림처럼 7x7에서 14x14로 upsampling을 하고 channel을 2048에서 256으로 줄인다. 그 다음 각 클래스별로 binary mask를 prediction하는 구조를 가지고 있다. 다시 말해 모든 클래스에 대해 mask를 생성하고 classification head에서 class 정보가 모일 것이라는 예측 결과를 이용하여 어떤 mask를 참조할 것인지 선택하는 것이다.

- YOLACT (You Only Look At CoefficienTs)
YOLACT 는 real-time으로 segmentation이 가능한 single stage network이다. 기본 backbone구조는 feature pyramid 구조를 가지고 와서 사용한다. 고해상도의 feature map을 가지고 사용을 할 수 있게되는데 가장 큰 특징은 mask의 prototype을 추출해서 사용한다는 것이다. Mask R-CNN에서는 실제로 사용하지 않더라도 80개의 class를 고려하고 있다고 한다면 80개의 각각 독립적인 mask를 한 번에 생성해내었다. 그중에서 classification된 결과에 따라서 하나를 참조하는 형태였다. 하지만 여기에서는 prototype이라고해서 mask는 아니지만 mask를 합성해낼 수 있는 기본적인 여러 물체의 soft segmentaion component들을 생성한다. 여기까지는 mask는 아니지만 mask로 합성될 수 있는 재료를 제공한다고 이해하면 된다.
prediction head에서 각 detection에 대해서 prototype들을 잘 합성하기 위한 계수들을 출력해준다. 그리고 이 계수들과 prototype을 선형 결합하여 각 detection에 적합한 mask response map을 생성해준다.
여기서 key point는 prototype의 수를 object의 수와 상관없이 작게 설정하여 선형 결합을 통해 다양한 mask를 생성하는 것이다. 만약 prototype의 수를 object의 수로 설정한다면 더 많은 비용이 발생할 것이기 때문이다.

- YolactEdge
이전 keyframe에 해당하는 feature를 다음 frame에 전달해서 feature map의 계산량을 획기적으로 줄였다. 또한 성능은 기존 방법과 유지할 수 있는 방법을 제시하였다.

Panoptic segmentation
기존의 instance segmentation은 배경에는 관심이 없었고 그저 움직이는 작은 물체들에 대해서만 관심을 가졌다. 배경 등에 관심이 있을 때는 semantic segmentation이 유리하긴 했지만 객체(instance)를 구별할 수 없다는 한계가 존재하였다. 그래서 이런 두 가지 문제 특성을 합친 새로운 문제로 Panoptic segmentation이 제시되었다.
- UPSNet
Backbone에서는 FPN을 사용하여 고해상도의 feature map을 뽑고 head branch를 여러개로 나눈다. 첫 번째는 Semantic head인데 fc 구조로 되어서 semantic map을 prediction 하게 되고 그 다음 branch로 instance head로 class의 detection과 box의 regression, mask를 추출하는 task를 담당한다. 그리고 이 모든 결과를 융합해주는 Panoptic Head가 들어가서 최종적으로 하나의 segmentation map으로 합쳐주게 된다.

각 head에서 나온 결과는 instance에 해당하는 mask, 각 물체들과 배경을 예측하는 mask들이 있다. 여기서 배경을 예측하는 mask는 최종 출력으로 바로 들어간다. 그리고 각 instance들을 bounding box가 아닌 전체 영상에 해당하는 위치에 다시 넣으면서 보강하기 위해 semantic head의 물체 부분을 masking을 하여 그 response를 instance response와 더해주어 최종 출력에 삽입을 한다. 아래 그림의 Y_i에서 box의 크기가 물체의 크기와 일치한다고 하면 전체 영역에서 어디에 위치해있는지를 조정해서 넣어주는 것이다.
물체와 배경에 소속되지 않는 unknown class를 고려하기위해 semantic mask map의 instance로 사용된 부분들을 제외하여 나머지 배타적인 부분들을 모두 unknown class로 합쳐 하나의 층으로 추가가 된다.

- VPSNet
VPSNet은 두 시간차를 가지는 두 영상사이의 phi라는 모션 맵을 사용해서 각 frame에서 나온 feature map을 모션에 따라서 warping을 해준다. 일단 모션 맵이라는 것은 두 개의 영상이 있으면 한 영상에서 다음 영상으로 어떤 포인트가 어디로 가는지의 대응점들을 모든 픽셀에대해서 가지고 있는 것을 말한다. 이를 활용하여 t-𝜏에서 뽑힌 feature를 마치 현재 target frame인 t에서 찍은 것과 마찬가지로 feature를 하나씩 옮겨준다. 그 다음 t에서 찍힌 feature와 warping된 feature를 합친다. 이렇게 함으로서 현재 frame에서 추출된 feature만으로도 대응하지 못하거나 보지이지 않게 가려져 있던 부분들도 이전 frame에서 빌려온 특징들 덕분에 더욱 높은 detection 성공률이 얻어지는 것이다. 그리고 여러 frame의 feature를 합쳐서 사용으로서 시간 연속적으로도 smooth한 segmentation이 될 확률도 높아진다.

FPN을 통해서 RoI feature를 추출해서 기존 RoI들과 tracking head를 통해 현재 RoI들이 어떻게 서로 연관이 되어있는지, 그 이전의 몇 번의 id를 가졌던 물체였는지를 찾아 연관성을 만들어주는 것이다. 새로 추출된 RoI가 기존의 추출된 RoI와 match시켜 tracking하는 것이다. 그리고 나머지는 UPSNet과 같이 BBox head, Mask head, Semantic head가 있고 각 head에서 나온 결과는 하나의 panoptic map으로 합쳐주게 된다.

Landmark localization
Landmark localization은 주로 얼굴이나 사람의 포즈를 추정하고 트래킹하는데 사용한다. 즉, 얼굴이나 사람의 몸통 등 측정 물체에 대해서 중요하다고 생각하는 특징 부분(keypoint=landmark)을 정의하고 추정, 추적하는 것을 말한다. 이때 ladmark는 이미 정의해놓은 것이다.

이런 keypoint를 찾기 위해서 box regression처럼 각 포인트의 x, y위치를 regression하는 Coordinate regression 방법이 있지만 부정확하고 일반화에 문제가 있다.
대안으로 heatmap classification이라는 방법으로 마치 semantic segmentation처럼 하나의 채널들이 하나의 keypoint를 갖게되고 각 keypoint들마다 하나의 class로 생각해서 그 keypoint가 발생할 확률 맵을 각 픽셀별로 classification하는 방법으로 대신 해결하는 것이 제시되었다. 하지만 이 방법도 성능은 좋지만 높은 계산량을 가진다는 단점이 있다.
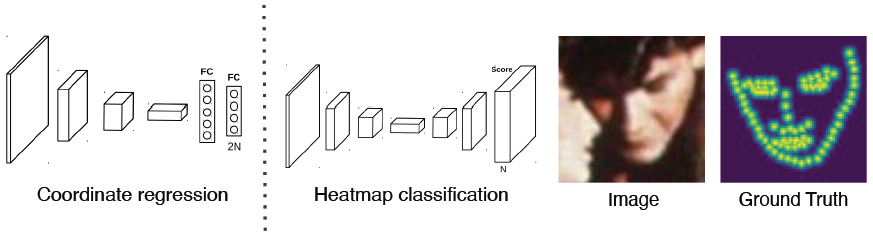
heatmap 표현은 각 위치마다 confidence가 나오는 형태의 표현인데 x,y가 label로 주어졌을 때 다음과 같은 heatmap으로 변환을 해야할 것이다. 그럴려면 location으로부터 heatmap으로 어떻게 변환할 것인가에 대해서 알아야한다.

# Generate gaussian
size = 6 * sigma + 1 #영상 크기(출력 해상도의 크기)
# x, y 좌표를 미리 정의
x = np.arange(0, size, 1, float)
y = x[:, np.newaxis]
x0 = y0 = size // 2 # 중간 점
# The gaussian is not normalized, we want the center value to equal 1
if type == 'Gaussian':
g = np.exp(-((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2))
elif type == 'Cauchy':
g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)
반대로 heatmap을 location으로 변환할 수 있어야할텐데 어떤 방법이 있을까...
Hourglass network
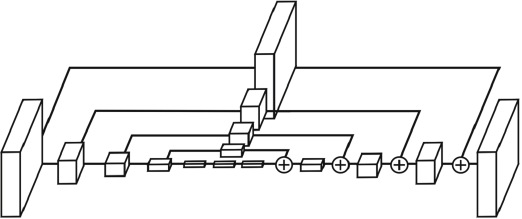
landmark detection에 맞춘 network가 제안되었는데 unet 구조와 비슷하며 여러 개로 쌓은 것과 같은 구조를 가지고 있다. 그리고 unet의 구조가 모래시계처럼 생겼다고 해서 Stacked Hourglass라고 부른다. 이렇게 설계한 이유는 첫 번째로 영상을 전반적으로 작게만들고 receptive field를 크게 만들어 landmark를 찾는 것이 좋겠다라고 생각한 것이고 receptive field를 크게 가져가서 큰 영역을 보면서도 skip connection이 있어 low level feature를 참고하여 정확한 위치를 특정하게끔 유도를 했다. 이것을 여러번 거쳐 점점 더 큰 그림과 디테일을 더욱 구체화하면서 결과를 개선해나아간다.

Hourglass network와 unet은 비슷한 구조이지만 다른 점은 다음과 같이 skip할 때 또 다른 convolution layer를 거치게 하였고 concatenation이 아닌 addition이 되도록 하였다. 이렇게 +를 함으로서 dimension이 늘어나지 않는다.
DensePose
신체 전체에대한 dense한 lanmark를 찾게되면 3d를 알게되는 것과 마찬가지이다. 이런 방법으로 DensePose하는 것이 제안되었다.

3d model의 각 부위를 2d로 펼쳐서 이미지 형태로 만들어 놓은 것을 좌표 표기법을 UV map이라고 한다. UV map에서의 한 점은 3D Mesh의 한 점과 일대일 매치가 된다. 3D Mesh는 triangle로 이루어져있는데 해당 triangle에 있는 점을 matching이 되고 각 triangle이나 점들에 고유한 id를 갖기 때문에 3D Mesh가 움직여도 tracking이 되면서 보존이 된다. 따라서 UV map의 좌표를 바로 출력하는 DensePose는 3D Mesh를 바로 출력하는 것과 같다.
그렇다면 texture는 어떻게 적용시킬까? texture는 이미지로 저장하는 것이 편하기 때문에 UV map이라는 표현이 그래픽스에서 3D Model에 texture를 입히기위해 고안된 것이다. 거기서의 좌표 특성을 DensePose에 응용한 것이다.
DensePose의 구조는 Mask R-CNN과 거의 동일하다. DensePose는 Faster R-CNN과 3D surface regression branch을 도입하여 확장한 형태의 모델이다.
아래 그림에서 Patch라고 되어있는 것은 각 바디 파트의 segmentation map이며 이와 같은 구조는 동일하더라도 입력 데이터와 출력 데이터와의 관계를 잘 설계함으로서 2D 구조의 CNN으로 3D를 잘 예측하는 스마트한 방법을 잘 설계했다고 말할 수 있다.
RetinaFace
RetinaFace에서는 classification(얼굴 판별), Box regression, 기본적인 5개의 landmark를 regression, 3d face mesh를 출력하는 다양한 task를 한 번에 풀도록 만들었다. 이러한 것은 Multi-task라고 부른다. 이렇게 Multi-task로 학습시키면 장점이 있는데 각 task마다 공통적으로 얼굴에대해 조금씩 다르다는 것을 알 수 있다. 이를 통해서 backbone network가 더 강하게 학습된다. 왜냐하면 gradient가 여러 곳에서 오면 공통적인 정보도 있을 것이고 조금 더 다른 정보도 있을 것이기 때문에 한 번에 update될 때 이런 모든 상황을 고려해서 잘 맞게 학습되어야한다. 다시 말해 데이터를 많이 본 것과 같은 효과를 내고 적은 데이터로도 강인한 학습 효과를 낼 수 있는 것이다.

Detecting objects as keypoints
- CornerNet
bounding box가 왼쪽 위, 오른쪽 아래의 점 두 개가 있으면 결정할 수 있는 network이다. backbone network에서 나온 feature map의 네 가지 head가 있는데 하나는 heatmap 표현을 통한 두 점을 각각 검출하도록 한다. 아래 그림처럼 top-left, bottom-right corner를 검출한다. 그 다음 embedding이라고 해서 각 포인트가 가지는 정보를 표현하는 head를 하나 더 두어 학습을 할 때 두 코너에서 나온 embedding point는 같은 object에서 나왔다면 같아야한다는 조건을 걸어 학습한다.
CornerNet는 구조가 간단하여 속도는 빠르지만 성능이 떨어지는 단점이 있다.

- CenterNet
CornerNet에서 성능이 떨어지는 단점을 보완하기 위해 top-left, bottom-right point에 center point까지 추가하여 학습을 진행하는 CenterNet를 제시하였다. (CenterNet(1))

또 다른 variant로 width, height, center만 있으면 최소한의 정보로 detection이 가능하다는 방법이 있다.(CenterNet(2))

이전에 설명한 모델들과 비교했을 때 다음에서 보듯이 CenterNet(2)가 가장 좋다는 것을 확인할 수 있다.

Further Question
- Mask R-CNN과 Faster R-CNN은 어떤 차이점이 있을까?
-> Fast R-CNN에서는 RPN(region proposal network)에 의해 나온 bounding box에 RoI Pooling을 사용하였다. 그리고 기존 RoI Pooling은 정수 좌표밖에 지원하였다. 하지만 Mask R-CNN에서는 RoIAlign이라는 새로운 Pooling layer를 제안하였고 RoIAlign에서는 interpolation을 통해서 소수점 픽셀 level의 pooling을 지원하게 되었다. 따라서 더욱 정교한 feature를 뽑을 수 있게 되고 그 뒷단의 성능이 향상되는 것으로 이어진다.
그리고 Fast R-CNN에서는 pooling된 feature 위에 올라가있던 Classifiaction과 box regression이 있었다. Mask R-CNN에서는 좀 더 확대해서보면 Mask branch가 있는데 아래 그림처럼 7x7에서 14x14로 upsampling을 하고 channel을 2048에서 256으로 줄인다. 그 다음 각 클래스별로 binary mask를 prediction하는 구조를 가지고 있다. 다시 말해 모든 클래스에 대해 mask를 생성하고 classification head에서 class가 모일 것이라는 예측 결과를 이용하여 어떤 mask를 참조할 것인지 선택하는 것이다.
- Panoptic segmentation과 instance segmentation은 어떤 차이점이 있을까?
-> 기존의 instance segmentation은 배경에는 관심이 없었고 그저 움직이는 작은 물체들에 대해서만 관심을 가졌다. 배경 등에 관심이 있을 때는 semantic segmentation이 유리하긴 했지만 객체(instance)를 구별할 수 없다는 한계가 존재하였다. 그래서 이런 두 가지 문제 특성을 합친 새로운 문제로 Panoptic segmentation이 제시되었다.
- Landmark localization은 human pose estimation 이외의 어떤 도메인에 적용될 수 있을까?
-> 기계의 동작에 대한 결함과 같은 것의 estimation?
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp Day-33] Computer Vision - Multi-modal learning (0) | 2021.09.17 |
|---|---|
| [Boostcamp Day-32] Computer Vision - Conditional Generative Model (0) | 2021.09.15 |
| [Boostcamp Day-30] Computer Vision - CNN Visualization (0) | 2021.09.14 |
| Fully Convolutional Networks(FCN) and VGGNet Segmentation Implemenation (0) | 2021.09.12 |
| [Boostcamp Day-29] Computer Vision - Object Detection (0) | 2021.09.10 |