Conditional generative model
스케치된 영상을 실제 사진과 같은 이미지로 변환해주는 문제를 생각해보자. 언어를 번역하는 것과 같이 서로 다른 두 도메인을 translating 한다라고 말한다. 그리고 하나의 조건이 주어졌을 때 어떤 이미지가 나오는 형태를 conditional generative model이라고 한다.

- Generative model vs. Conditional generative model
Generative model은 랜덤하게 sample을 생성한고 Conditional generative model은 랜덤한 sample에 condition이 주어진 것이다.

Conditional generative model의 예로는 audio super resolution, machine translation, article generation with the title 등이 있다.
- Generative Adversarial Network(GAN)
GAN 모델은 주로 위조 지폐 범인과 경찰을 예로 들어 설명을 한다. 범인은 Generator라고하고 Discriminator는 경찰이라고 하면 Generator는 Discriminator를 잘 속이기 위한 Data를 생성하고 Discriminator는 Generator에서 만든 가짜 data를 잘 판별할 수 있도록 진행이 되는 것이다.
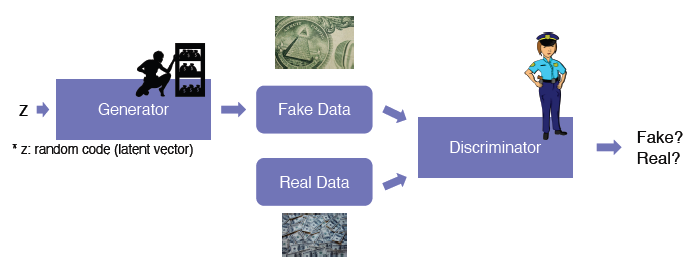
- Image-to-Image translation
어떤 이미지를 다른 이미지로 translation하는 것으로 style transfer, super resolution, colorization 등으로 적용된다.

- low resolution to high resolution(super resolution)
저해상도를 고해상도로 출력을 해주는 방법으로 대표적인 conditional GAN의 적용 사례이다.

다음과 같이 어떤 이미지를 colorizing한다고 했을때 real image로 흰색, 검은색 밖에 없다고 하자. 입력 영상이 주어졌을 때 mse 또는 mae를 사용하여 학습하였을 때 회색 이미지가 나온다. 왜냐하면 흰색 이미지일때 틀리는 경우가 있고 검은색 이미지일때 틀리는 경우가 있기 때문에 그 중간 값인 회색 이미지를 출력하기 때문이다. 반대로 gan loss를 사용하게되면 회색 이미지가 출력되었을 때 잘못된 이미지라고 판별할 수 있게 된다.
Pix2Pix
image translation은 한 이미지 스타일을 다른 스타일로 변환하는 문제를 의미한다.

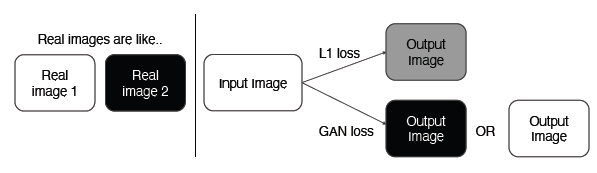
이런 task를 cnn 구조를 이용해서 학습기반으로 처음 정리한 연구가 바로 pix2pix이다. pix2pix에서는 loss function을 다음과 같이 정의하여 사용한다.
gan loss만 사용하게 되면 x와 y가 독립적으로 fake인지 real인지 판별하기 때문에 x가 y와 비슷한 영상을 가질 수가 없다. 따라서 L1 loss를 추가하여 x가 y와 비슷한 영상을 가질 수 있게 해준다.


CycleGAN
이전 pix2pix에서는 아래 그림의 왼쪽에서 처럼 x와 y의 이미지가 pair의 형태로 주어져야 했다. 그런데 반대로 unpair로 활용할 수 있는 방법이 없을까 하는 의문에서 나온 것이 CycleGAN이다.

다시 말해 CycleGAN은 non-pairwise dataset 형태의 도메인끼리 translation을 할 수 있는 방법이라고 할 수 있다.

- Loss function of CycleGAN
CycleGAN loss = GAN loss (in both direction) + Cycle-consistency loss

GAN loss(adversarial loss) : A에서 B로 가거나 B에서 A로 translation하는데 사용

GAN loss만 사용하게 되면 Mode Collapse라는 문제가 발생하게 되는데 input에 상관없이 그냥 하나의 output만 계속 출력하는 형태로 학습이 되어버리는 것이다.

Cycle-consistency loss : Mode Collapse 문제를 해결하기 위해 제안된 것으로 안의 스타일만 보는 것이아닌 Contents도 유지되어야한다라는 것이다. 진행은 다음과 같이 된다.

Perceptual loss
GAN은 학습하기 어렵다는 문제가 있다. 그래서 GAN없이 high-quality image를 얻기 위한 방법으로 Perceptual loss라는 것이 있다.
- GAN loss(adversarial loss)
- 상대적으로 학습하기 힘들다
- pre-train된 network가 필요없다
- 다양한 곳에 적용할 수 있다
- Perceptual loss
- 학습하기 편하고 코딩하기 편하다
- pre-train된 network가 필요하다

- Image Transform Net : input 이미지가 주어지면 하나의 원하는 스타일이 정해져있는 network이다.
- Loss Network : 학습된 loss를 측정하기 위해 학습된 vgg16(image classification model)을 사용한다. 또한 학습할 때 fix되어 update 되지 않는다.

- Feature reconstruction loss : transform된 이미지가 contents를 그대로 유지하고 있는지를 권장해주는 loss

- Style reconstruction loss : Feature reconstruction loss가 contents를 그대로 유지하는 것이라면 Style reconstruction loss는 style을 유지해주는 loss