728x90
Introduction
[이전 ViT의 문제]
- ViT는 다양한 task에서 성공적인 결과를 얻었지만 많은 연산량으로 이러한 성능을 낸다.
- Swin Transformer의 경우 window-baes self-attention을 제안하는데 이는 complexity를 줄일 수 있도록 도와주지만 shifted operator가 ONNX 또는 TensorRT를 적용하기에 어려움을 준다.
- Twins SVT의 경우 window-baes self-attention와 spatial reduction attention과 spatially separable self-attention을 제안하고 deployment에 친화적이지만 연산량을 쉽게 줄일 수 있는 방법은 아니었다.
- CSWin Transformer도 SOTA 성능을 보이지만 throughput은 낮았다.
위 문제들을 해결하기위해 local, global dependency 모두 잡는 SepViT를 제안한다.
- mobilenet의 depthwise separable convolution에서 착안하여 depthwise separable self-attention module을 개발했고 depthwise self-attention과 pointwise self-attention으로 구성되어있다. 각각 mobilenet의 depthwise, pointwise convolution과 일치한다. depthwise self-attention은 각 윈도우 내의 local feature를 잡기위해 사용되고, 반면에 pointwise self-attention은 윈도우간의 연결을 통해 표현력을 향상시킨다.
- local window의 global 표현을 가지기위해 window token embedding을 개발하는데 아주 적은 비용만으로 윈도우 간의 관계를 attention할 수 있다.
- AlexNet에서의 grouped convolution 아이디어에서 착안하여 grouped self-attention을 적용하고 성능을 향상시켰다.
Overview

Depthwise Self-Attention(DWA)
- input feature map에 window partition을 수행한다. 각 윈도우는 feature map의 input channel로 볼 수 있으며, 서로 다른 윈도우는 다양한 정보를 포함한다.
- 각 윈도우에는 윈도우 token이 만들어지는데 이것은 global 표현을 제공하고 pointwise self-attention module에 따른 attention 관계를 모델링하기위해 사용된다.
- DWA는 각 윈도우 내의 모든 pixel token들, 이와 일치하는 window token으로 수행된다.
- 이 window-wise operation은 mobilenet의 depthwise convolution layer와 상당히 비슷하고 각 채널내의 공간 정보를 얻기위해 초점을 맞추었다.
- 수식으로 표현하면 다음과 같다.
![]()
z: featue tokens (pixel과 window token으로 구성)
$W_Q, W_K, W_V$: 각각 self-attention을 수행하기위한 query, key, value
Window Token Embedding
- window간의 관계를 attention하기위한 직관적인 solution은 모든 pixel token을 사용하는 것이다. 하지만 이것은 상당한 비용이 들 것이다.
- 더 나은 attention위해 window token embedding을 제안하는데 이것은 각 sub-window의 중요한 정보를 요약한 하나의 토큰으로 이득을 보는 것이다.
- window token은 고정된 zero vector로 초기화하거나 zero로 초기화된 학습가능한 vector를 사용할 수 있다.
- DWA를 통과하는 동안 각 윈도우에서의 window token과 pixel token들 사이 간의 정보의 상호 작용이 일어난다. 그리고 window token은 window의 global 표현을 학습할 수 있다.
- 효율적인 window token 덕분에 아주 적은 연산량으로 window 간의 attention 관계를 모델링 할 수 있다.
Pointwise Self-Attention (PWA)
- mobilenet의 유명한 pointwise convolution은 서로 다른 채널로 정보를 얻어내는데 유용하다. 이런 원리로 각 window들 간의 연결을 이루어내기위해 pointwise self-attention (PWA) module을 개발한다.
- PWA는 주로 window 간의 정보를 얻거나 input feature map의 마지막 표현을 유지하기위해 사용된다.
- 더 구체적으로 보면, DWA의 output으로 window token과 feature map을 추출하는데 window token은 window간의 attnetion 관계를 모델링하기위해 사용되고 LN(layer normalization)과 GeLU activation function을 통과하여 attention map을 생성한다. 반면에 다른 추가 operation없이 PWA의 value branch로 feature map을 처리한다.
- 이렇게 window 형태의 feature map과 attention map을 사용하여 window 간의 attention 연산을 수행한다.
- 수식으로 표현하면 다음과 같다.
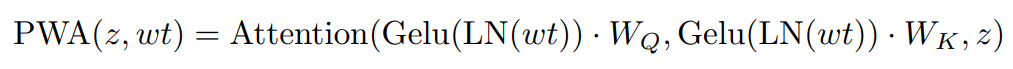
wt: window token
z: all of the windows
Grouped Self-Attention

- 여러 개의 인접한 sub-window를 연결하여 더 큰 window를 만드는데, 이것은 window를 group으로 나누고 window group 내에서 depthwise self-attention을 수행하는 것과 비슷하다. 이러한 방법으로 grouped self-attention은 long-range visual dependency를 잡을 수 있다.
- 비용적인 측면에서는 grouped self-attention이 depthwise separable self-attention과 비교하여 추가적인 비용이 발생하지만 더 나은 성능을 보여준다.
- SepViT에서는 network 후반에 depthwise separable self-attention block과 grouped self-attention을 번갈아 수행한다.
SepViT Block

$\ddot{z}^l$: DWA output
$\hat{z}^l$: PWA output
$z^l$: SepViT block l output
$\dot{z}^l$: feature map
$\dot{w}t$: learned window token
Comparison of Complexity

728x90