Introduction
NLP에서 Transformer가 성공적인 결과를 얻은 것에 영감을 얻어 본 논문에서는 이미지를 패치로 분할한 후 그 패치들을 linear embedding의 sequence로 사용했다고 한다. 여기서 이미지 패치들은 NLP에서의 토큰들(단어들)과 같이 사용되었다.
하지만 Transformer는 CNN보다 Inductive Bias가 부족하기때문에 불충분한 데이터로 학습하게되면 일반화가 잘 안된다.
Vision Transformer (ViT)
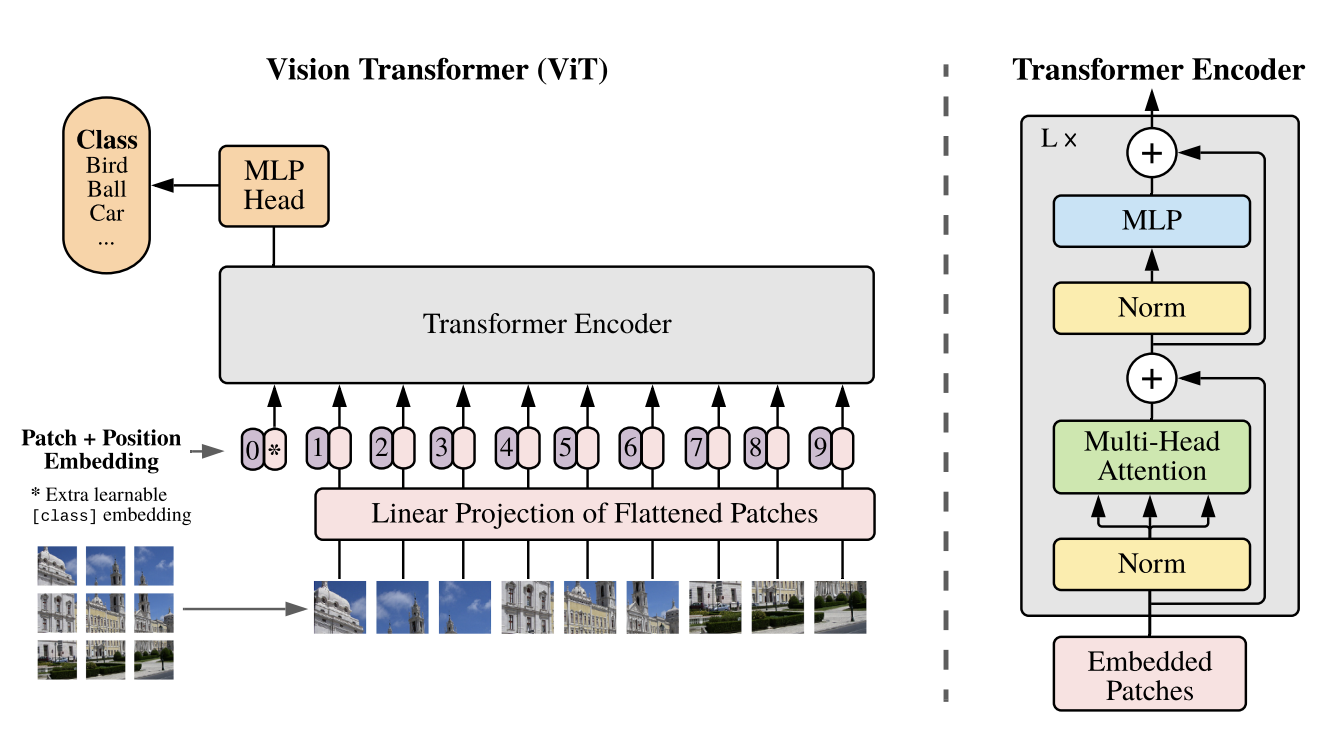
보통 Transformer는 1D token embedding의 sequence를 입력한다. 하지만 2D 이미지를 다루기 위해서 ViT는 HxWxC 크기의 이미지를 flatten된 2D 패치의 sequence, Nx($P^2 \cdot C$) 크기로 reshape한다. 여기서 (H, W)는 입력 이미지의 해상도이고 C는 채널 수, (P, P)는 각 이미지 패치의 해상도이고 N = HW/$P^2$는 패치들의 수이다. 또한 N은 Transformer의 input sequence length로써 다뤄진다고 볼 수 있다.
패치들을 flatten하고 학습가능한 linear projection을 통해 D 차원으로 매핑한다. 그리고 BERT의 [class] 토큰처럼 맨 앞의 embedding patch도 학습가능한 embedding으로 사용한다.
position embedding은 patch embedding에 추가되어 positional 정보를 유지한다. 이때 학습가능한 1D position embedding을 사용하였다. (2D position embedding으로 사용했었을때 명확하게 성능 차이를 못느꼈다고 한다.)
position embedding은 다른 해상도의 이미지를 잘 fine-tuning하기위해 추가했다고 한다. 또한 패치들 간에 모든 공간 관계를 학습하기위함이 있다고 한다.
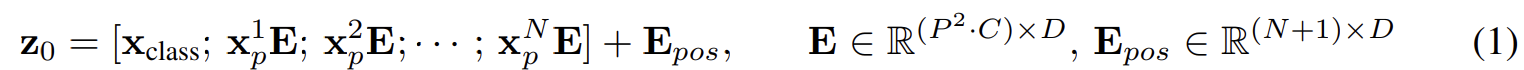
이후 Transformer encoder의 출력으로 얻은 값은 이미지를 나타내는 y로 다루어진다.
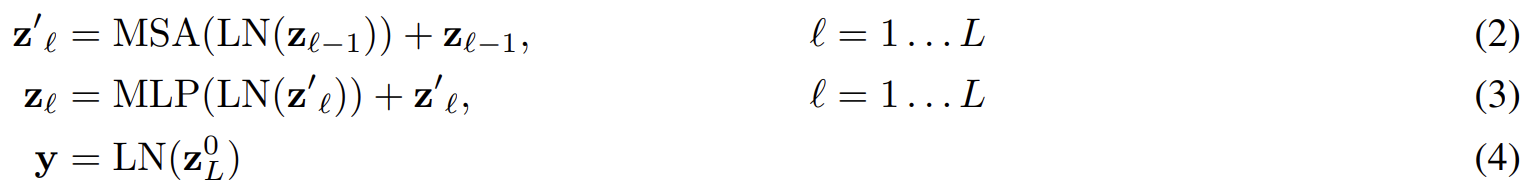
Hybrid Architecture
위 Eq. 1의 E는 CNN으로 뽑은 feature map에서 patch를 추출하여 적용할 수 있다. 이러한 구조를 Hybrid Architecture라 한다.
Fin-Tuning and Higher Resolution
본 논문에서는 fine-tuning을 할 때 pre-training할 때보다 높은 해상도의 이미지로 학습했다고 한다. 이렇게 높은 해상도로 학습할때 patch size는 같게 유지한다.
vision transformer는 임의의 sequence length를 다룰 수 있다. 하지만 pre-train된 position embedding은 아마 더이상 의미가 없을 수 있다. 그래서 본래 이미지에 있는 위치 정보를 포함하는 pre-trainded position embedding의 2D interpolation을 수행한다.
이렇게 resolution 적응과 path 추출은 이미지의 2D structure에 대한 inductive bias를 vision transformer에 집어넣는다.
Code Review
timm코드를 가져와보겠습니다. (불필요?한 코드은 삭제했습니다.)
Overall
class VisionTransformer(nn.Module):
def __init__(
self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, global_pool='token',
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, init_values=None,
class_token=True, no_embed_class=False, fc_norm=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
weight_init='', embed_layer=PatchEmbed, norm_layer=None, act_layer=None, block_fn=Block):
self.patch_embed = embed_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
self.blocks = nn.Sequential(*[
block_fn(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, init_values=init_values,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)])
# Classifier Head
self.fc_norm = norm_layer(embed_dim) if use_fc_norm else nn.Identity()
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def _pos_embed(self, x):
if self.no_embed_class:
# deit-3, updated JAX (big vision)
# position embedding does not overlap with class token, add then concat
x = x + self.pos_embed
if self.cls_token is not None:
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
else:
# original timm, JAX, and deit vit impl
# pos_embed has entry for class token, concat then add
if self.cls_token is not None:
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
x = x + self.pos_embed
return self.pos_drop(x)
def forward_features(self, x):
x = self.patch_embed(x)
x = self._pos_embed(x)
x = self.blocks(x)
x = self.norm(x)
return
def forward_head(self, x, pre_logits: bool = False):
x = self.fc_norm(x)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x- __init__
- self.patch_embed: patch embedding layer
- self.blocks: transformer encoder
- fc_norm: 보통 LayerNorm을 사용
- self.head: classification head (Linear)
- _pos_embed: PE와 cls_token을 더함
- PE를 더하고 cls_token을 추가하는 것과 cls_token을 추가하고 PE를 더하는 것의 차이: 그냥 DeiT-3가 지원되면서 두 가지로 나누어짐 (DeiT-3는 PE를 더하고 cls_token을 추가해야하나봄)
PatchEmbed
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x)
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x- self.proj: 위 코드처럼 Conv2d로 feature map을 뽑거나 CNN기반 네트워크를 사용(Hybrid)하여 feature map을 뽑음
- self.norm: feature map을 flatten 후 LayerNorm으로 Normalization
Block(Transformer Encoder)
class Block(nn.Module):
def __init__(
self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., init_values=None,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.ls1 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.ls2 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
x = x + self.drop_path1(self.ls1(self.attn(self.norm1(x))))
x = x + self.drop_path2(self.ls2(self.mlp(self.norm2(x))))
return- LayerNorm -> MSA -> LayerScale -> Drop path
- LayerNorm -> MLP -> LayerScale -> Drop path
LayerScale은 https://arxiv.org/pdf/2103.17239v2.pdf에서 나오며 더 깊은 image transformer의 성능을 향상시키기위해 적용한다.