
Introduction
Convolution의 중요한 개념으로 다음 세 가지를 말할 수 있다.
- sparse interaction
- weight sharing
- equivariant representations
각각의 개념들에 대해서 리마인드해보자.
sparse interaction
sparse interaction은 위 그림의 윗부분처럼 이전 layer의 output이 다음 layer의 input이 될 때 fully connected가 아니라 일부만 연결이 되어서 유의미한 feature만 찾을 수 있는 것을 말한다.
parameter share
sparse interaction에서 그림의 아래부분처럼 파라미터를 공유하지 않을 경우 input의 하나하나 모두 연결되어 전체적으로 데이터를 한 번에 본다. 하지만 윗부분처럼 파라미터를 공유할 경우 필터 하나가 input의 여러 곳을 보기 때문에 데이터를 더 효율적으로 볼 수 있다. (여기서 파라미터를 공유한다는 의미는 필터 하나로 공유한다는 말이다.) 이 때문에 이미지 내의 객체가 어디에 있든 찾을 수 있다.
equivariant representations
간단히 말해서 input이 바뀌면 ouput도 바뀐다는 것을 의미한다. 예를 들어서 input 이미지에서 객체의 위치가 변하면 output도 동일하게 변한다는 것이다.
invariance 특성과 헷갈릴 수 있는데 invariance의 경우 FC 레이어(또는 pooling)를 통해 나온 output이 input 이미지에서 객체의 위치가 변해도 동일하다는 것을 의미한다.
정리하면 equivariant는 input의 위치 정보가 변하면 output의 위치 정보도 변해야 한다는 것을 의미하고 invariance는 input의 위치 정보가 변해도 output의 classification 결과는 동일해야한다는 것을 의미한다.
“Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data.”
ViT의 저자는 위와 같이 주장한다. 즉, Transformer는 CNN과 달리 많은 양의 데이터가 필요하다는 얘기이다.
본 논문에서는 CNN, Transformer 두 개의 갭을 채우기위해 sparse interaction과 weight sharing 특성을 가지면서 중요한 feature를 볼 수 있는 architecture를 개발한다.
바로 ViT보다 더 작고 compact한 버전인 ViT-Lite를 소개하며 CIFAR-10 데이터셋에서 90% 정확도를 가진다. 그리고 sequence pooling를 적용하고 CVT(Compact Vision Transformer)로 ViT-Lite를 확장한다. 또한 tokenization 단계에 convolutional block을 추가하고 CCT(Compact Convolutional Transformer)를 만든다. 이렇게 추가하여 CIFAR-10 데이터셋에서 98% 정확도에 도달하였다. 그리고 DeiT와 같은 비슷한 크기의 모델보다 더 나은 성능을 보였다고 한다.
Can vision transformers be trained from scratch on small datasets?
Method
본 논문에서는 세 가지의 모델을 제안한다.
- ViT-Lite
ViT-Lite는 본래 ViT 구조와 거의 같지만 small-scale learning에 적합한 크기를 가진다.
- Compact Vision Transformers (CVT)
CVT는 SeqPool을 사용하여 전체 sequence를 pool한다. 따라서 SeqPool은 [class] 토큰을 대체할 수 있다.
- Compact Convolutional Transformers (CCT)
CCT는 convolutional tokenizer를 활용하여 더 풍부한 token을 생성하고 local 정보를 유지한다. convolutional tokenizer는 ViT와 비교하여 patch들끼리의 관계를 더 잘 학습할 수 있게한다.
Transformer-based Backbone
encoder는 transformer block으로 구성되어있으며 각각 MHSA, MLP block이 포함된다. 또한 Layer Normalization, GELU, dropout을 적용한다. Positional embedding은 learnable 또는 sinusoidal을 사용할 수 있고 둘 다 효과적인 성능을 보인다.
Small and Compact Models
ViT 구조 중 가장 작은 ViT-Base는 12개의 attention head를 가지는 12 layer transformer encoder를 포함하고 head당 64 dimension, MLP block에서는 2048 dimensional hidden layer를 포함한다. 16x16 크기의 patch size를 가지고 85M 파라미터를 가진다.
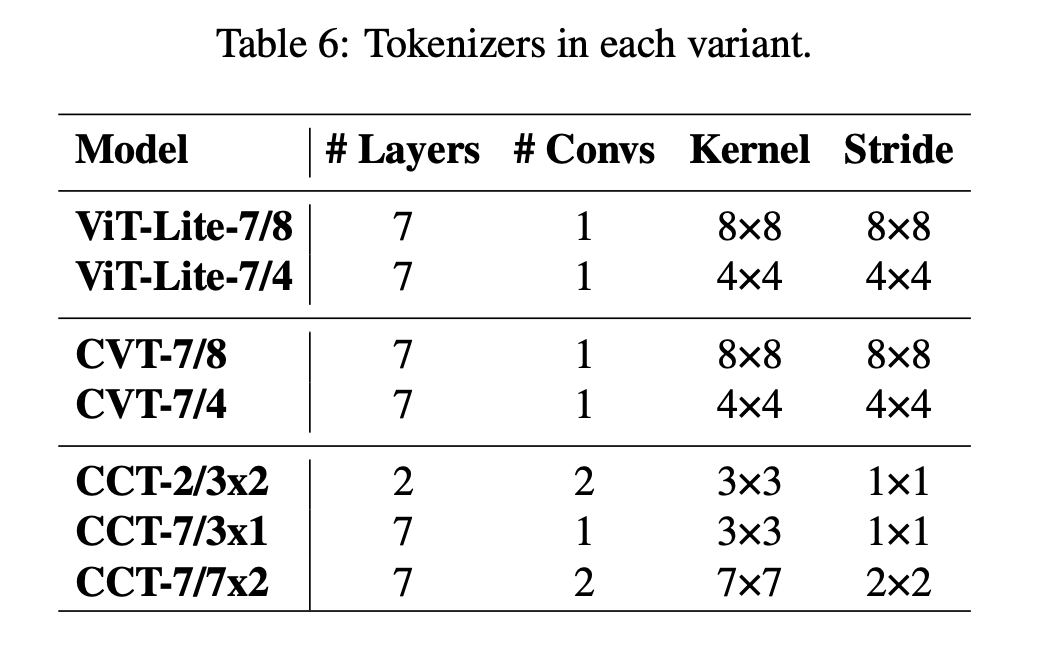
하지만 본 논문의 저자는 2 layers, 2heads, 128 dimensional hidden layer 구조를 제안한다. 다음 표를 보면 어떻게 backbone 구조를 변형했는지 알 수 있고 가장 작은 모델(CCT-2)은 0.22M 파라미터를 가지고 가장 큰 것 (CCT-14일 것 같음)은 3.8M 파라미터를 가진다고 한다.
또한 데이터셋에 따라 patch size를 다음과 같이 변형했다고 한다.
SeqPool
output sequence token들을 pooling하는 attention 기반 method, SeqPool을 제안한다. motivation은 ouput sequence에 input 이미지의 각 다른 부분들끼리의 관계 정보를 포함하는 것이다. 이 정보는 성능을 향상시켜줄 것이고 learnable token과 비교해서 추가적인 파라미터가 없다. 또란 이러한 변화는 더 적은 token을 가지고 학습하기 때문에 연산량이 약간 줄어든다.
Linear 레이어를 통해 output sequence를 다음과 같이 매핑한다.
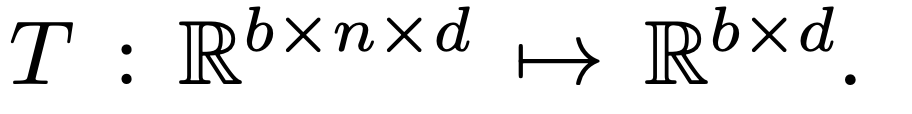
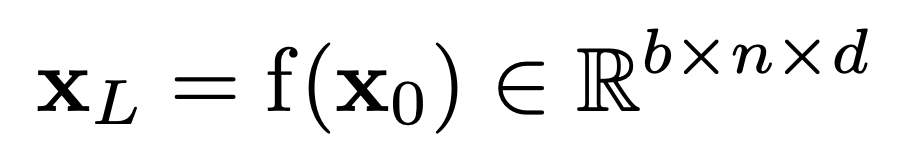
XL: L 번째 layer의 transformer encoder f의 output
b: batch size
n: sequence length
d: total embedding dimension
XL은 다시 linear 레이어 g(XL)∈Rd×1 에 들어가고 softmax를 통과한다.
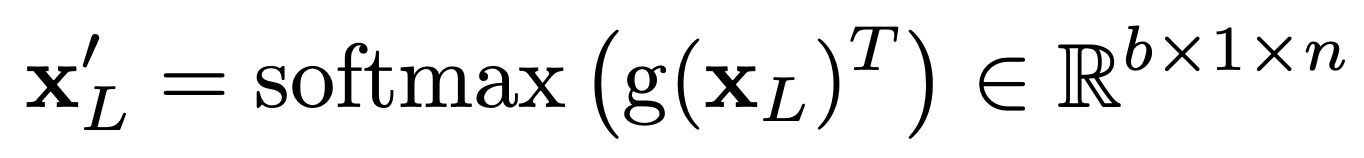
그리고 X`_L과 X_L의 행렬곱을 해서 중요한 가중치를 얻는다.
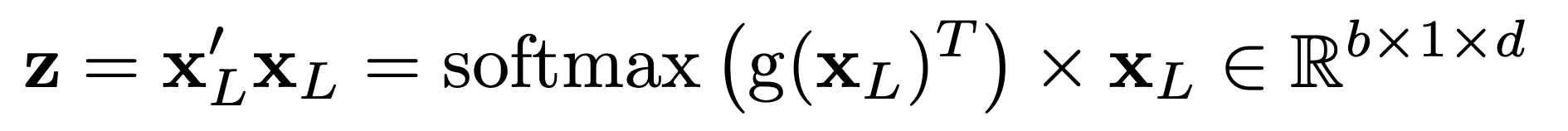
마지막으로 flatten을 하고 classifier에 넣어준다.
learnable, statick method 포함 여러 pooling method로 실험을 해보았는데 learnable pooling이 가장 좋은 성능을 보였다고 한다. 저자는 그 이유가 각 embedding된 patch는 같은 양의 entropy(정보)를 가지고 있지 않기 때문이라고 한다. 또한 sequence pooling은 공간적으로 sparse한 데이터 간의 정보를 더 잘 활용할 수 있게 해준다고 한다.
Convolutional Tokenizer
모델에 inductive bias를 집어넣기위해 ViT-Lite와 CVT에서 embedding과 patch를 convolutional block으로 바꾼다. 이 block은 하나의 convolution과 ReLU, max pool로 구성되어있다. 이미지 또는 feature map이 주어진다면 다음과 같은 수식이 적용될 것이다.
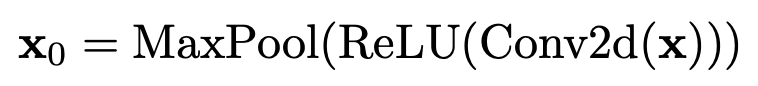
convolution과 max pool은 overlapping할 수 있으며 inductive bias 주입을 통해 성능을 향상시킬 수 있다. 또한 지역적인 공간 정보를 유지할 수 있게 해준다. 추가로 convolutional block을 사용함으로써 ViT와 같은 모델에 유연하게 붙일 수 있다. 더 이상 이미지 해상도에 따른 patch size를 나눠야할 필요가 없어진다.
convolution으로 이미지를 embedding해서 더 효율적으로 더 풍부한 토큰을 만들 수 있을 것이라고 생각한다고 한다. 이 block은 kernel size, stride, padding으로 downsampling ratio를 조정할 수 있고 반복적으로 downsampling할 수도 있다. self-attention은 token 개수에 따라 quadratic한 시간, 공간 복잡도를 가지고 token의 개수는 input feature map의 해상도와 동일하다 그래서 downsampling을 한 결과에서는 더 적은 token을 가지므로 훨씬 연산량이 감소한다. 그리고 이러한 tokenization은 positional embedding이 따로 없어도 될 정도로 좋은 유연성을 가진다.
Experiments
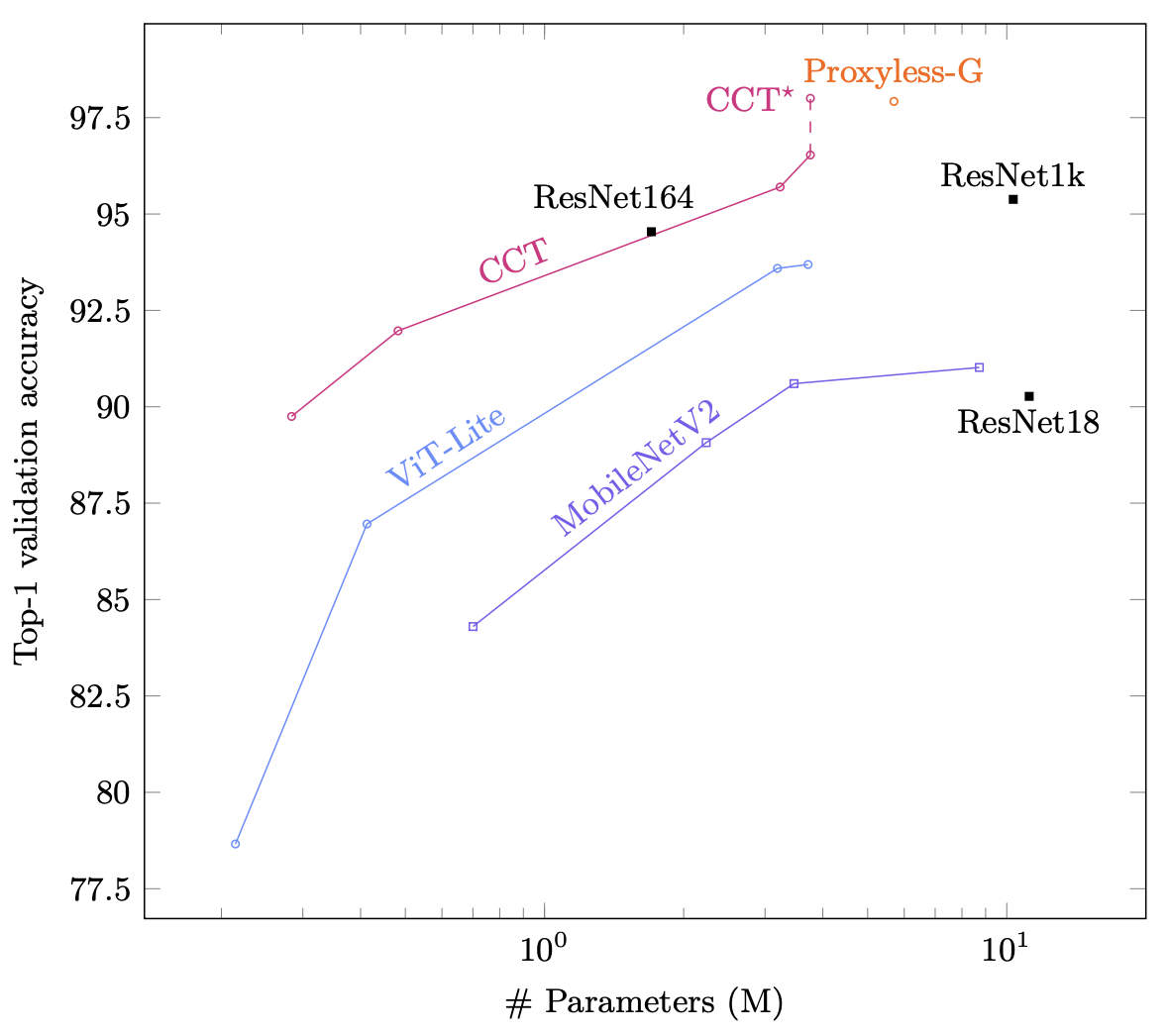

한 가지 의문이 드는 점은 5000 epoch 학습하여 가장 좋은 성능을 얻었다고 했는데 과연 5000 epoch 학습하는 것이 효율적인 학습이라고 할 수 있을까하는 것이다.
'Deep Learning' 카테고리의 다른 글
| Object Detection (R-CNN, SPPNet, Fast-RCNN, Faster-RCNN, YOLO) (0) | 2022.11.14 |
|---|---|
| [Paper] CvT: Introducing Convolutions to Vision Transformers (0) | 2022.11.08 |
| [Paper] SepViT: Separable Vision Transformer (1) | 2022.10.23 |
| [Paper] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions (0) | 2022.10.03 |
| Generate Text Decoding Methods (1) | 2022.09.21 |