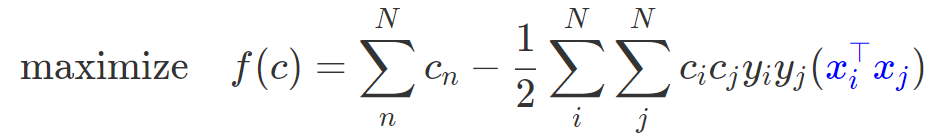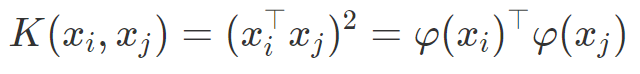데이터가 linear하게 있지 않는 것을 확인 할 수 있는데 이것은 logistic regression이나 linear support vector machine (SVM)을 학습시킬 수 없다. 그렇다면 어떻게 해야 학습 시킬 수 있을까?
바로 더 높은 차원(2차원 -> 3차원)에 데이터를 매핑시키는 것이다. 이때 어떤 $\varphi$라는 function을 사용해서!
teddykoker.com
$\varphi$를 차수가 2인 polynomial kernel이라고 할 수 있다. 만약 위 데이터에 적용한다면 다음과 같이 시각화 할 수 있다.
teddykoker.com
그럼 이제 linear SVM를 학습할 수 있는 수식을 작성할 수 있다.
teddykoker.com
수식 전체를 이해하지 못해도 괜찮다. $x_i^T x_j$ 가 내적된다는 것만 집중하면된다. 만약 이 식에 kernel function $\varphi$을 적용하고 싶다면 그냥 각 $x_n$에 $\varphi$을 씌워주면 된다.
teddykoker.com
그런데 만약 $\varphi(x_n)$을 N 번, $\varphi ( x_i^T ) \varphi(x_j)$ 내적을 N^2 번 연산한다고 하면 상당한 연산량이 들 것이다. 이 문제를 해결하기위해 이때 바로 kernel trick을 사용하는 것이다.
그리고 만약 함수 $K: \mathbb{R}^2 \times \mathbb{R}^2 \mapsto \mathbb{R}$ 가 있고 더 낮은 차원의 공간에서 연산을 수행할 수 있게 해준다면 연산량을 굉장히 줄여줄 수 있을 것이다!
다음 간단한 유도식을 보자.
위 유도식으로 알 수 있는 사실은 데이터를 3차원에 올리고 내적을 계산하는 것과 2차원에서 내적을 계산하고 제곱의 합한 것과 동일하다는 것이다. 그리고 2차원에서 내적을 계산하고 제곱의 합하는 방식이 훨씬 연산이 적게 일어난다는 것이다.
이 사실을 통해 K는 다음과 같이 표현할 수 있다.
또한 linear SVM은 다음과 같이 다시 작성할 수 있다.
Random Fourier Features
위에서 설명한 kernel function 보다 연산량을 감소시킬 수 있는 것으로 Random Fourier Features가 있다. Random Fourier Features는 K와 근사한 randomized feature map $z: \mathbb{R}^L \mapsto \mathbb{R}^R$ 을 사용한다.
푸리에 변환으로 z를 샘플링하여 근사시킬 수 있는데 구체적으로 다음과 같이 작성할 수 있다.
여기서 $\omega \sim \mathcal{N}_R(0, I)$가 spherical gaussian에서 샘플링된다. 이를 통해 L차원 공간에서 내적할 필요가 없게되고 R차원 공간에서 수행할 수 있게된다.
Attention
대부분의 LM(language model)들은 다음 scaled-dot-product attention을 사용한다.
$ Q, K, V \in \mathbb{R}^{L \times d}$이고 L은 sequence length, d는 hidden dimension이다.
위에서 softmax를 전개하면 다음과 같다.
$1_L$은 1로 이루어진 L 길이의 vector이고 코드는 다음과 같이 작성할 수 있다.
def attention(q, k, v):
l, d = q.shape
a = np.exp(q @ k.T * (d ** -0.5))
d_inv = np.diag(1 / (a @ np.ones(l)))
return d_inv @ a @ v
여기서 attention matrix A를 잘 보면 $\mathbb{R}^{L \times L}$ shape을 가진다는 것을 깨달을 수 있다. 즉, A가 어떤 연산을 수행하개되면 time, space complexity가 quadratic하게 증가한다는 것이다.
Performer
Softmax Kernel Performer는 random Fourier feature를 사용하여 Attention complexity를 줄였다. 위 Attention의 A의 식에서 normaiization 요소에 해당하는 $\sqrt{d}$는 이미 적용했다고 가정하고 없앤 후 간단히 다음과 같이 표현해보자.
그리고 이제 softmax kernel $K_{softmax}: \mathbb{R}^d \times \mathbb{R}^d \mapsto \mathbb{R}$를 정의해보자.
softmax kernel을 사용하는 것은 A에서 어떤 element의 연산이 일어나는 것으로도 표현할 수 있을 것이다.
$q_i, k_j$는 각각 Q, K에서 i 번째, j 번째 row vector이다.
이것은 다시 feature mapping z를 사용하여 더 낮은 차원에서 근사할 수 있다.
$K_{softmax}$는 Gaussian kernel function에 대한 다음과 같은 유도식을 얻을 수 있다.
마지막으로 Random Fourier Feature를 사용하여 $K_{softmax}$에 근사한 random feature mapping $z$를 얻을 수 있다.
Code
def prm_exp(self, x):
# ==== positive random features for gaussian kernels ====
# x = (B, T, hs)
# w = (m, hs)
# return : x : B, T, m
# SM(x, y) = E_w[exp(w^T x - |x|/2) exp(w^T y - |y|/2)]
# therefore return exp(w^Tx - |x|/2)/sqrt(m)
xd = ((x*x).sum(dim = -1, keepdim = True)).repeat(1, 1, self.m)/2
wtx = torch.einsum('bti,mi->btm', x, self.w)
return torch.exp(wtx - xd)/math.sqrt(self.m)
def forward_single_attn(self, x):
k, q, v = torch.split(self.kqv(x), self.emb_s, dim = -1)
kp, qp = self.prm_exp(k), self.prm_exp(q) # (B, T, m), (B, T, m)
D = torch.einsum('bti,bi->bt', qp, kp.sum(dim = 1)).unsqueeze(dim = 2) # (B, T, m) * (B, m) -> (B, T, 1)
kptv = torch.einsum('bin,bim->bnm', v, kp) #(B, emb_s, m)
#print(kptv.shape, D.shape)
y = torch.einsum('bti,bni->btn', qp, kptv)/D.repeat(1, 1, self.emb_s) #(B, T, emb_s)/Diag
return y