728x90
- sentence에 각 word에 대한 position을 위해 어떤 정보를 추가하는 것을 "positional encoding"이라 부른다.
- 첫 번째 아이디어로 첫 번째 word를 0, 마지막 time step을 1을 뜻하는 [0, 1] 범위로 각 time step에 숫자를 지정하는 것이 있을 수 있다. 이런 아이디어에는 특정 range 안에 얼마나 많은 word가 있는지 파악할 수 없다는 것이다.
- 또 다른 아이디어로 각 time step에 숫자를 선형적으로 배치하는 것이다. 첫 번째 word는 "1"이 주어지고 두 번째 word는 "2"가 주어지는 방식이다. 이 방법의 문제는 value가 너무 큰 값을 가지게 될 뿐만아니라 model이 training에서보다 더 긴 sentence에 직면할 수 있다는 것이다.
- 따라서 다음과 같은 이상적인 조건을 만족해야한다.
(1) 각 time step에 대한 unique한 encoding을 output해야한다.
(2) 어떤 두 time step 사이의 거리는 다른 길이를 가지는 sentence에서 일정해야한다.
(3) model은 어떤 노력없이 더 긴 sentence에서도 generalize해야한다.
(4) deterministic 해야한다.
Proposed Method
- 한 sentence에서 특정 position에 대해 information을 포함하는 d 차원 vector
- 이 제안된 encoding은 model 자체에 통합되지 않는다. 대신에 이 vector는 한 sentence에서 position에 대한 information을 각 word에 제공하는데 사용된다.
- input sentence에서 원하는 position을 t라고 한다면 vector $p_t$가 그것에 해당하는 encoding이다.
- output vector $p_t$를 도출할 function은 다음과 같이 정의될 수 있다.
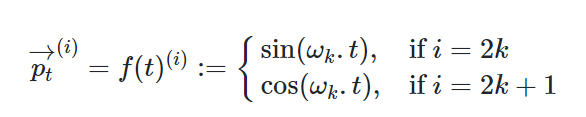
- frequency는 vector 차원에 따라 감소된다. 그리고 $2\pi ~ 10000*2\pi$의 파장에서 geometric progression을 형성한다.
- 또한 각 frequency에 대한 sine과 cosine 쌍을 포함하는 vector인 positional embedding $p_t$를 떠올릴 수 있다.
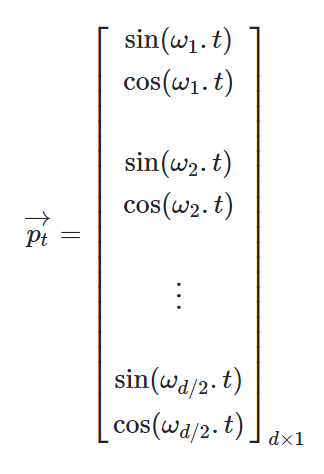
Intuition
- 다음과 같이 숫자를 이진법으로 표현한다고 하자.

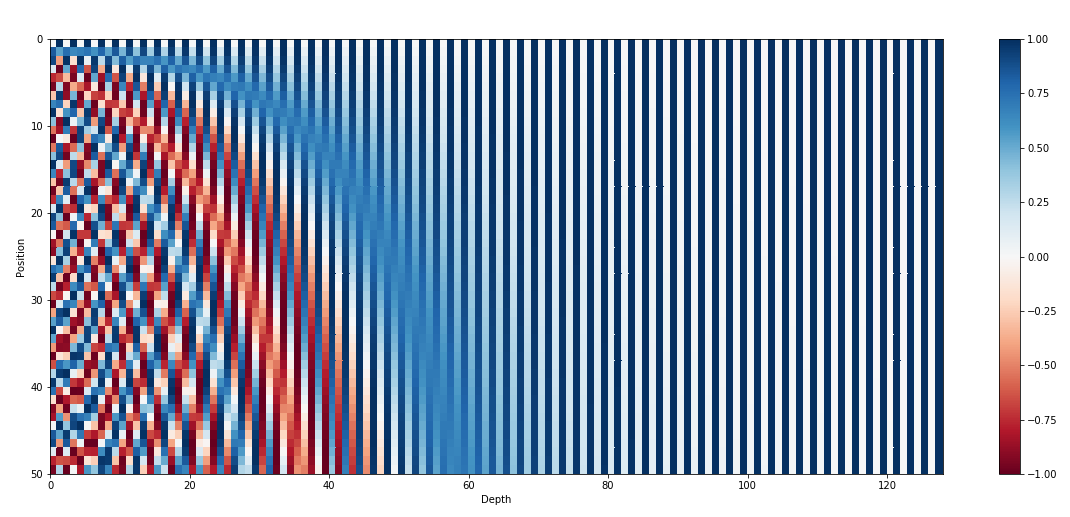
- 이진수를 사용하는 것은 실수 범위에서 공간 낭비가 될 수 있다. 그래서 대신에 "Sinusoidal function"을 사용할 수 있다. 그리고 아래 그림과 같이 frequency를 감소시키면 빨간색 bit에서 주황색 bit로 갈 수 있다.
왜 positional embedding은 word embedding과 concatenation하는 대신에 summation을 하는 것일까?
- concatenation과 다르게 summation은 모델의 parameter를 저장한다.
- 위에 있는 Fig 2.를 잘 보면 전체 embedding 중 처음 몇 dimension들이 position에 대한 information을 가지고 사용된다은 것을 알 수 있다.
- 그리고 word의 semantic이 positional encoding을 방해하는 것을 피하기 위해 처음 몇 dimension에 저장되지 않는 방식으로 설정되었을 수 있다.
- 최종 Transformer는 positional information에서 word의 semantic을 분리할 수 있을 것이라 생각한다.
[reference]
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
https://timodenk.com/blog/linear-relationships-in-the-transformers-positional-encoding/
728x90