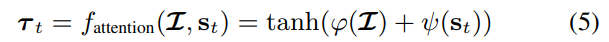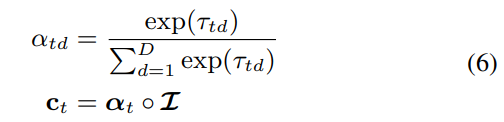Abstract
- attention modeling(R2AM)을 사용한 recursive RNN을 제안하며 다음과 같은 이점을 가지고 있다.
(1) parametrically 효율적이고 효과적인 이미지 feature extraction을 가능하게하는 recursive CNN을 사용
(2) N-gram의 사용을 피할 수 있는 RNN에 구현된 학습된 character-level language model
(3) soft-attention mechanism을 사용하여 model이 조직화된 방식으로 image feature를 선택적으로 활용될 수 있으며 standard backpropagation framework 내에서 end-to-end 학습을 수행 할 수 있다.
1. Introduction
- unconstained STR task에 집중하고 attention modeling(R2AM)의 recursive RNN을 개발
- 본 논문에서는 다음과 같은 세 가지 주요 contribution을 제시한다.
(1) 같은 parameteric capacity에서 vinilla CNN보다 더 효율적인 image feature extraction을 위해 weight-sharing을 하는 recursive CNN
(2) character-level language model의 implicit learning 수행을 위해 앞서 언급한 recursive CNN으로부터 추출된 image feature들 위의 RNN들. RNN들은 dictionary로부터 수동으로 정의된 N-gram의 필요없이 training data로부터의 word strings에서 자연적으로 제시한 sequential dynaminc 문자들을 자동적으로 학습할 수 있다.
(3) charactre sequence를 읽을 때 "soft" deterministic image feature selection을 수행하고 standard backpropagation에서 end-to-end로 train할 수 있는 sequential attention 기반의 modeling mechanism
2. Mehodology
2.1 Character sequence model review
- 많은 text recognition method들은 system pipeline의 첫 번째 단계로 단어의 개별 문자를 capture하는데 초점을 맞춘 다음 statistical language model 또는 visual structure prediction을 적용하여 잘못 분류된 문자를 고치거나 개선한다.
- character sequence model의 detail은 "Deep structured output learning for unconstrained text recognition."을 참고
- 본 논문에서는 이 baseline method를 base CNN으로 부른다.
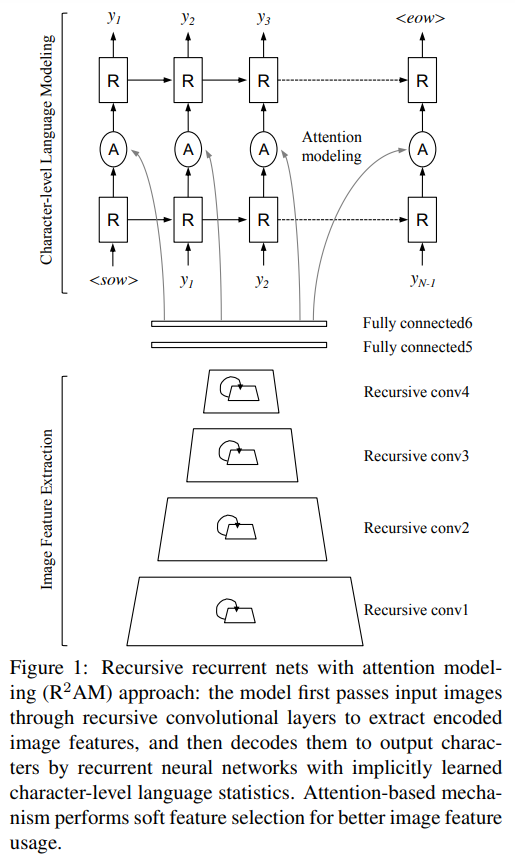
2.2 Recursive CNNs for image feature extraction
2.2.1 Recursive convolutional layers
- 앞서 언급한 character sequence model의 성공 핵심은 전체 input image에서 계산하는 multiple convolutional layer를 작용해서 character prediction 동안 contextual dependency를 capture하는 능력이다.
- character prediction을 위해 더 긴 범위릐 contextual dependency를 사용하기위해 base CNN model을 개선할 수 있는 한 가지 방법은 각 convolutional layer 또는 deeper network에 대해 더 큰 kernel size를 사용하여 해당 receptive field size를 증가시키는 것을 고려하는 것이다. 하지만 이 방법은 파라미터 수와 model complexity를 증가시킨다.
- 모델 capacity를 control하면서 더 긴 data의 의존성을 확장하는 또 다른 방법은 base CNN network를 recursive 또는 recurrent로 만드는 것이다.
- recursive 또는 recurrent convolutional layer를 사용함으로써 network architecture는 각 layer와 같은 convolutional weight matrix를 여러 번 재사용하는 것으로 parameter의 총 개수가 증가하는 것 없이 임의의 깊이가 될 수 있다.
- recursive CNN은 같은 parameter capacity에서 본래 CNN의 깊이를 증가시키고 CNN보다 훨씬 compact한 feature를 response한다.
- t time step에서 recursive convolutional layer의 instance는 input image/feature를 다음과 같이 response하여 feeding된다.

- recursive/recurrent convolutional layer에 대해 더 자세한 discussion은 "Recurrent convolutional neural network for object recognition"을 참고
2.2.2 Untying in recursive convolutional layers

- 위 Eqn. 1에서 모든 weight들이 같은 내부값을 공유하도록 제한한 것이다. 즉, 이것들은 함께 "tied"된 것이다.
- recursive convolutional layer의 "untied" 변형 사용을 제안
- 다른 layer에서 다른 수의 channel을 가지고 recursive weight를 더 자유로게 다룰 수 있다.
- time step t = 0에서 untying feed-forward weight에 의하면 Eqn. 1은 다음과 같이 된다.

- 이로써 어떤 recursive convolutional layer의 channel 수는 untied weight에 의해 조절될 수 있으며 전체적인 계산 비용을 control 할 수 있다.
- fig 2. 를 보듯이 같은 logic을 사용하여 untie recurrent convolution layer를 사용할 수 있다.
- recursive version이 모든 task에서 recurrent version을 능가하며 recurrent model보다 더 효과적으로 tie된 weight를 사용
2.3 RNNs for character-level language modeling

- Base CNN: Section 2.1에서 설명한 하나의 character position에 집중한 각 loss function, multiple loss function과 함께 학습되는 Baseline character sequence CNN
- Base CNN + RNN_1c: image-captioning에서 파생된 single-layer RNN이다. 추출된 image feature는 첫 번째 time step에서만 RNN으로 보내진다. 그리고 t - 1에서 RNN의 예측 character는 end-of-word가 나올때까지 time t에 feeding된다.
- Base CNN + RNN_1u: RNN이 모든 time step에 image feature를 받는다. 따라서 character prediction은 모든 time에서 image feature와 이전 hidden state로 결정된다.
- Base CNN + RNN_2u: RNN_1u를 한 번더 쌓은 것
- Base CNN + RNN_2f: RNN 2개를 쌓은 것으로 두 번째 layer RNN에 image feature를 access한다. 이 방법에서 첫 번째 RNN은 character-level language modeling에 집중하고 두 번째 RNN은 language statistic과 image feature를 결합하는 것에 집중한다.
2.4 Attention modeling
- 일반적으로 attention 기반의 image 이해는 hard-attention과 soft-attention으로 분류된다. hard attention model은 일련의 discrete glipse location을 선택하는 방법을 배우며, loss gradient를 일반적으로 다루이 어렵기 때문에 학습하기 어려울 수 있다. 이번 실험에서는 soft-attention model을 선택하였으며 standard backpropagation과 end-to-end으로 학습할 수 있다.
- fig 3. 의 마지막 Base CNN + RNN_attn이 본문에서 설명한 attention modeling function이다.
- 모든 output step t에서 attention function은 image feature와 첫 번째 RNN의 output으로 결정된 energy vector를 계산한다.