728x90
Abstract
- attention 기반의 encoder-decoder 프레임워크가 scene text recognition에서 인기가 있는 이유는 시각적, 의미적 domain으로부터 recognition clues를 통합하는데 있어서 우수하기 때문이다.
- 하지만 최근 연구에서 두 clues는 특이한 문자 모양과 같은 어려운 문자에서는 서로 잘 맞지 않아 어긋날 것이고 문제를 완화하기위해 위치와 같은 제약 사항을 도입한다.
- 어떤 성공에도 불구하고 내용이 없는 positional embedding은 의미있는 이미지 영역과 관련이 거의 없다.
- 이 논문에서는 positional encoding과 관련된 시각과 의미를 수립한 MDCDP(Multi-Domain Character Distance Perception)이라 불리는 모듈을 제안한다.
- MDCDP는 positional embedding을 attention mechanism에 따르는 시각적, 의미적 feature들 둘 다 query로 사용한다.
- 자연스럽게 문자 사이의 시각적, 의미적인 거리를 설명하는 positional clue를 encoding한다.
- 정확한 거리 modeling을 guide하기위해 MDCDP를 여러번 쌓아서 CDistNet이라 명명한 architecture를 개발했다.
- 따라서 시각적, 의미적 정렬은 다양한 어려움에도 잘 구축되어 있다.
1. Introduction
- Scene text recognition task는 수 년동안 여러 연구가 수행되었음에도 여전히 여러 어려운 문제들에 직면해있다.
- attention 기반의 encoder-decoder method들이 이 task에서 인상적인 성능을 이루었다.
- 어떤 논문에서는 text 이미지로부터 시각적 feature를 추출하고 encoder 쪽에 있는 주석으로부터 의미적 feature를 encoding한다.
- decoding하는 동안 text 이미지는 문자단위로 식별된다.
- 각 time step에서 의미적 feature는 시각적 공간에서 관련성을 정렬하기위해 query vector로써 사용된다. 이를 통해 두 종류의 feature들은 통합되고 문자 수준 인식 결정(charactre-level recognition decision)이 도출된다.
- 하지만 최근 연구에서 두 clues는 드물게 불규칙한 텍스트에서 쉽게 일치하지 않는다. 이것은 시각적 clue가 약할 때, 의미적 clue가 시각적으로 대응되는 부분을 안정적으로 찾지 못하기 때문이라고 할 수 있다.
- 더욱이 이런 문제는 의미적 feature이 점차 강화되고 decoding된 문자의 누적으로 긴 텍스트에서 가장 잘 나타난다.
- 위의 문제로 비추어 볼 때 여러 연구들은 sinusoidal-like positional embedding이나 다른 것들로 encoding한 정보들로 불일치를 완화하기위해 문자 위치를 활용한다.
- 어느 정도의 문제를 해결했음에도 몇몇에서는 시각적 feature와 상호작용하기 위해 내용이 없는 positional embedding을 사용하고 문자의 위치들과 이미지 영역 사이의 안정적인 연관성을 확립하기 힘들다. 이것은 내용을 인식하는 것보다 위치의 순서를 제약하는 것에 가깝다. 게다가 위치와 의미적 공간 사이의 관계를 무시한다.
- 이 논문에서는 앞서 언급한 문제들을 극복하기위해 MDCDP라 불리는 모듈을 개발하였다고 한다.
- 비슷하게 존재하는 연구들은 고정된 positional embedding이 초기화된다. 하지만 다르게 encoder에서의 feature는 먼저 self-attention을 거치고나서 attention mechanism에 따른 시각적, 의미적 feature들과 상호작용하기위한 query vector로써 사용된다.
- 이것은 두 domain들에 positional 향상을 준다. 향상된 두 feature들의 결과는 visual, semantic 거리 인식 표현으로써 보여질 수 있다. 이것은 두 domain들에서 문자 간의 관계를 encoding한다. 이전 position feature는 다음 MDCDP의 query vector로써 사용되고 좀 더 attention에 집중된 visual-semantic 정렬을 얻을 수 있다.
- 이런 아이디어로부터 이 논문에서는 MDCDP를 여러번 쌓은 CDistNet이라 명명한 architecture를 제안한다.
- positional feature를 visual과 semantic features query로 사용하는 MDCDP를 제안한다. 이것은 처음에 visual과 semantic 거리 인식 위치 modeling으로 사용되고 attention에 집중된 visual-semantic 정렬에 우수하게 작동된다.
- CDistNet은 문자 거리를 잘 인식하고 어려운 text 인식을 위해 MDCDP를 여러번 쌓았다.
2. Related Work
clues들을 어떻게 활용하는지에 따라 semantic-free, semantic-enhanced, position-enhanced method로 대략 분류할 수 있다.
2.1 Semantic-free Methods
- 주로 이미지의 visual feature를 활용하여 recognition을 구현하지만 문자들 간의 관계는 명시적으로 modeling되지 않는다. 예를 들어 어떤 논문에서는 CNN으로 추출한 visual feature를 sequence로 reshape하고나서 RNN과 CTC loss로 modeling된다.
- RNN에 의해 decoing되는 것보다 segmentation 기반의 method들이 pixel 단위의 문자 segmentation, prediction을 직접적으로 수행한다. 하지만 보통 문자 단위의 주석들이 요구되서 항상 유용하지는 않다. 게다가 이런 method들의 성능은 semantic clue를 잘 modeling하지 못했기때문에 제한적이다.
2.2 Semantic-Enhanced Methods
- visual feature를 강화하고 attention 기반의 encoder-decoder framework를 사용하기위해 semantic clue를 강조한다.
- attention mechanism을 scene text recognition에 도입하였는데 이것은 1D 이미지 feature와 문자 sequence의 embedding을 사용하였다. 이를 통해서 semantic 정보가 고려되는 것이다.
- 한 논문에서는 semantic 정보 활용을 guide하기위해 언어 모델을 제시하고 인상적인 결과를 얻었다.
- 하지만 이럼에도 불구하고 특히 긴 text에서 문자와 이미지 영역 사이의 정렬이 잘 안되는 것이 관찰된다.
2.3 Position-Enhanced Methods
- recognition을 쉽게하기 위해 character position encoding을 개발한다. RARE와 같은 모델은 초기 작업에 recognition network에 feeding을 하기 전 text를 rectify하기위한 STN을 사용한다. 이것은 position clue 활용의 초기 form이다.
- 비록 발전된 rectification model들이 개발되었지만 단독으로는 서로 다른 clue들의 시너지 활용을 일으킬 수 없다.
- 반면에 positional encoding은 일반적으로 attention mechanism이 local이 아닌 transformer 기반의 모델에 적용된다. 예를 들어, sinusoidal positional embedding은 character position 안에 기록되기위해 적용된다.
- embedding이 고정되었다는 것을 가정하고 position 정보를 활용하기위해 학습 가능한 embedding이 개발되었다.
- attention drift([참고] input image의 target 영역에 각 feature vector를 정확하게 연결할 수 없는 현상)를 억제하기 위해 TextScanner는 문자가 올바른 순서로 읽히고 올바르게 분리되도록 하기 위해 order segmentation map을 제안했다.
- RobustScanner는 dynamical fusion mechanism과 함께 position enhancement branch를 제안한다.
- position과 이미지 영역 간의 안정적인 대응을 거의 구축하지 못한 내용이 없는 positional embedding이 사용된 것과 달리 본문에서는 시각적, 의미적 feature에 positional embedding을 주입하고 어려운 text를 쉽게 인식하는 multi-domain 거리 인식 모델링을 확립한다.

3. Methodology
- attention 기반의 encoder-decoder framework에 속하는 end-to-end network
- encoder는 세 개의 branch로 구성되어있으며 각각은 encoding visual, positional, semantic information이다.
- decoder는 세 종류의 information을 MDCDP module로 통합한다. 그리고 MDCDP에서 positional branch는 visual과 semantic branch를 강화하고 새로운 hybrid distance-aware positional embedding을 작동하기위해 활용된다.
- 작동된 embedding은 visual과 semantic domain에서의 문자별 관계를 기록한다. 그리고 다음 MDCDP의 positional embedding으로 사용된다. 이것은 attention에 집중된 visual-semantic 정렬 작동을 쉽게한다.
- MDCDP module을 여러 번 쌓으면 더 정확한 거리 modeling을 달성하는 CDistNet이다.
- 문자들은 마지막 MDCDP module의 output을 기반으로 순차적으로 decoding된다.
3.1 Encoder
1. Visual Branch
- visual branch는 text 이미지들을 rectify하는 전처리로써 TPS(Thin-plate-splines)를 활용한다.
- backbone으로 ResNet-45와 Transformer unit이 적용되고 이것은 local과 global spatial dependencies를 capture한다.
- Transformer unit은 layer당 1024 hidden units를 가지는 세 개의 self-attention encoder이다.
- 과정은 다음 수식으로 설명할 수 있다.
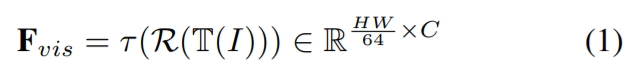
- $I$: input text image
- $T$: TPS block
- $R$: ResNet-45
- $\tau$: Transformer unit
- ResNet-45는 기존 size의 1/8로 width, height 모두 downsampling된다.
2. Semantic Branch
- semantic branch는 학습 동안 이전에 본 문자들을 encoding한다.
- test 동안에는 이전에 decoding된 character들은 현재 semantic feature로 encoding되고 이것은 각 time step으로 update된다.
- start token의 embedding은 첫 번째 문자가 decoding될 때 사용된다.
3. Positional Branch
- 초기에 positional branch는 text에서의 문자 위치를 encoding한다.
- 문자 위치가 주어지면 우선 one-hot vector를 진행하고 "attention all you need"에서 embedding을 얻는 것과 같은 sinusoidal positional embedding을 사용한다.
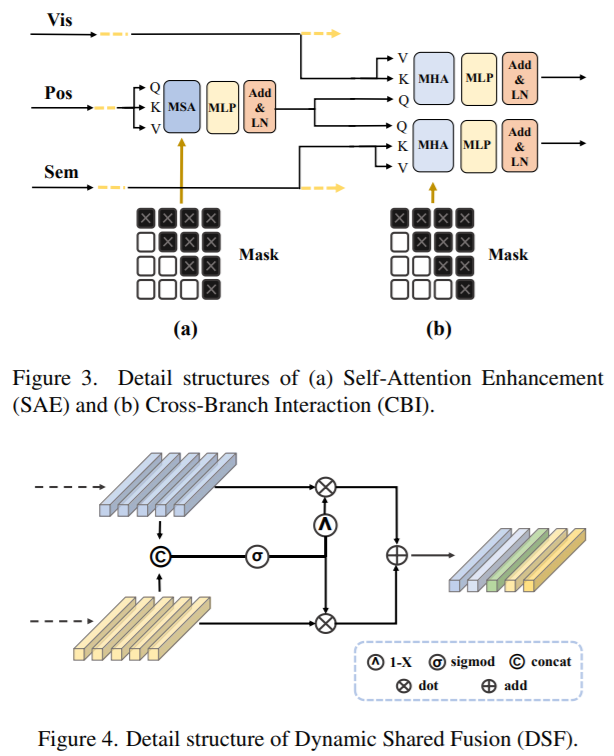
3.2 MDCDP
- MDCDP는 세 가지 part로 구성된다. positional feature 강화를 위한 self-attention enhancement, positional feature를 활용하여 visual과 semantic branch를 query하는 cross-bransh interaction, positional-enhanced representation 획득 그리고 visual과 semantic 공동 embedding을 얻기 위한 dynamic shared fusion
- 결론적으로 세 개의 feature들은 합쳐지고 distance-aware representation을 얻게된다.
1. SAE (Self-Attention Enhancement)
- encoder로부터의 초기 positional embedding으로 SAE는 vanilla Transformer의 multi-head self-attention block을 사용하여 embedding을 강화하지만 계산 비용을 줄이기 위해 dimension의 절반을 사용한다.
- 위 fig 3. (a)에서 보면 self-attention block의 query vector의 상부 삼각형 마스크가 적용돼 time step을 거치면서 정보가 유출되는 것을 방지한다.
- RobustScanner는 positional embedding을 사용하여 visual feature를 query하기 전에 이러한 enhancement를 설정하지 않는다. query vector는 항상 다른 문자 sequence에 고정된다. 반면에 본문의 enhancement는 보다 targeting된 positional embedding 학습을 가능하게한다.
2. CBI (Cross-Branch Interaction)
- fig 3. (b)를 보듯이 enhanced positional embedding은 query vector로 다뤄지고 visual, semantic branch에 병렬적으로 feeding된다.
- visual branch에 적용될 때 text 이미지에서 다음 문자는 이전 decoding된 문자 위치를 사용하여 찾는다. sub-branch는 CBI-V로 불린다.
- 두 branch는 interaction이후 강화된다. 상부 삼각형 mask도 동적 update 특성으로인한 information 유출을 예방하기위해 semantic branch에 적용된다.
- 이전 연구에서는 visual feature와 interact하기위한 query로 semantic feature를 사용한다. RobustScanner는 position에서 visual로 query를 추가하여 확장하고 positional-enhanced decoding을 활성화한다. 하지만 이것은 semantic branch를 활용하지 않는다.
- 반면에 본문에서는 visual, semantic domain 모두에 대한 positional 기반 intermediate enhancement로 interaction을 공식화한다. 이것은 visual 뿐만 아니라 semantic feature를 강화하고 multi-domain character distance를 설명하는 것으로 이해할 수 있다.
3. DSF (Dynamic Shared Fusion)
- fig 4를 보듯이 DSF는 두 개의 positional-enhanced feature를 input으로 받는다. 이것들은 channel이 두 배인 hybrid feature로 concatenate된다. 그리고 feature는 1x1 conv를 거쳐 channel이 절반으로 된다.
- 그 이후 gating mechanism은 weight matrices로 변환하도록 design되었다. 이것은 visual과 semantic feature에 element-wisely 적용된다. 그리고 visual과 semantic domain에 의해 feature의 dynamic fusion이 형성된다.
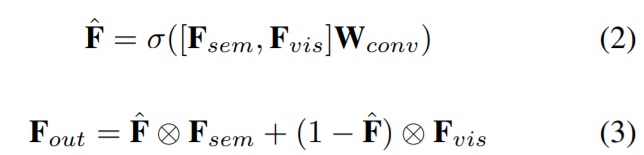
- $F_{sem}, F_{vis}$: 각각 positional-enhanced semantic, visual feature를 가리킨다.
- DSF의 특성 중 하나는 weight가 다른 MDCDP module들끼리 서로 공유된다는 것이다.
- 결과적으로 DSF는 이전 attention 학습으로 feature fusion을 분리시킬 뿐만 아니라 network modeling을 쉽게 해준다.
728x90