728x90
Introduction
- ViT가 ImageNet과 같은 midsze dataset (양이 중간 크기인 데이터셋)에서 CNN보다 떨어지는 이유를 다음 두 가지로 꼽았다.
- 간단한 토큰화 (hard하게 patch split하는 것을 말함)는 중요한 local structure를 모델링할 수 없고 train 효율이 떨어진다. 따라서 더 많은 학습 샘플들을 필요로 한다.
- ViT의 attention bachbone은 고정된 연산량과 제한된 학습 샘플은 제한된 feature들로 이어진다.
- 위 가설을 검증하기위해 ViT-L/16과 ResNet50에서 학습된 feature들의 차이를 다음과 같이 시각화하였다.

- (1) ResNet (2) ViT (3) T2T-ViT 내부 그림
- ResNet과 T2T-ViT에서 녹색 박스를 보면 Desired Local Structure(Edge, Line, Texture)를 잘 파악한다.
- ViT에서의 빨간 박스는 0 또는 너무 큰 값을 가지는 feature map을 가지게 된다. 이것은 ViT가 너무 Global Attention에만 집중하여 Local Structure에 대해서 잘 파악하지 못하는 문제때문이라고 한다.
Tokens-to-Token ViT
위 한계들을 극복하기위해 Tokens-to-Token Vision Transformer를 제안한다.

- 해당 모델은 이미지를 token들로 structurize하고 local structure 정보를 모델링한다. 그리고 이러한 방법은 token 길이를 반복적으로 줄여준다.
- T2T process는 다음 두 개의 step을 가진다.
- Re-structurization
- Soft Split(SS)
Re-structurization
Fig. 3에 나와있는 것처럼 앞단의 transformer layer에서 얻은 토큰들 T는 self-attnetion block (Fig. 3에서의 T2T Transformer)에 들어가서 변환된다.
$T^{'} = MLP(MSA(T))$
$T^{'} \in l \times c$
이후 $T^{'}$는 reshape된다.
$I = Reshape(T^{'})$
$I \in h \times w \times c$
$I = h \times w$
Soft Split
- Fig. 3에 나와있는 것처럼 local structure를 모델링하고 token의 길이를 줄이기위해 soft split을 적용하였다.
- 특히, re-structureization($I$)로부터 token이 생성될 때 정보 손실을 피하기위해 patch들을 overlap하여 split한다.
- 이로써 얻은 각 patch는 주변 patch들과 상관관계를 가지게 되면서 주변 patch들간의 강력한 prior(사전지식)을 가지게 된다.
- split한 각 patch들을 하나의 토큰으로 concat함으로써 local 정보를 주변 pixel, patch들로부터 얻을 수 있다.
- soft split 후 출력된 token $T_o$의 길이는 다음과 같이 계산된다.

p: padding
k: kernel size
s: stride
T2T module
- T2T process를 반복적으로 수행함으로써 T2T module은 Token 길이는 점차 줄어들고 공간 구조를 변환할 수 있다. 공간 구조를 변환한다는 것의 의미는 soft split을 통해 주변 patch들과 concat하면서 변환되는 것을 말하는 것 같다.

일반적인 경우 (16x16) ViT보다 T2T module이 더 긴 token을 가짐으로써 MAC(Multi-Adds)와 메모리 사용량이 크다. 따라서 Performer와 같은 효율적인 Transformer를 선정함으로써 제한된 GPU 메모리에서 메모리 사용량을 줄일 수 있었다고 한다.
Overall Architecture

- 맨 처음 input image에 대해서는 Re-structurization을 진행하지않고 바로 Soft Split을 진행한다.
- 마지막 T2T process를 진행한 후에는 class token을 concat하고 Sinusoidal Position Embedding(PE)를 더한다.

d: hidden dim
b: number of layer
$T_f$: 마지막 T2T module layer에서 얻은 tokens
E: Position Embedding
- 논문 저자들은 T2T Transformer layer를 Performer layer와 Transformer layer를 선장하였다. (두 layer 실험 결과에서 accuracy는 0.2~0.3% 차이로 Transformer layer가 약간 높게 나오고 params는 같으며 MACs는 Performer layer가 더 낮게 나온다.)
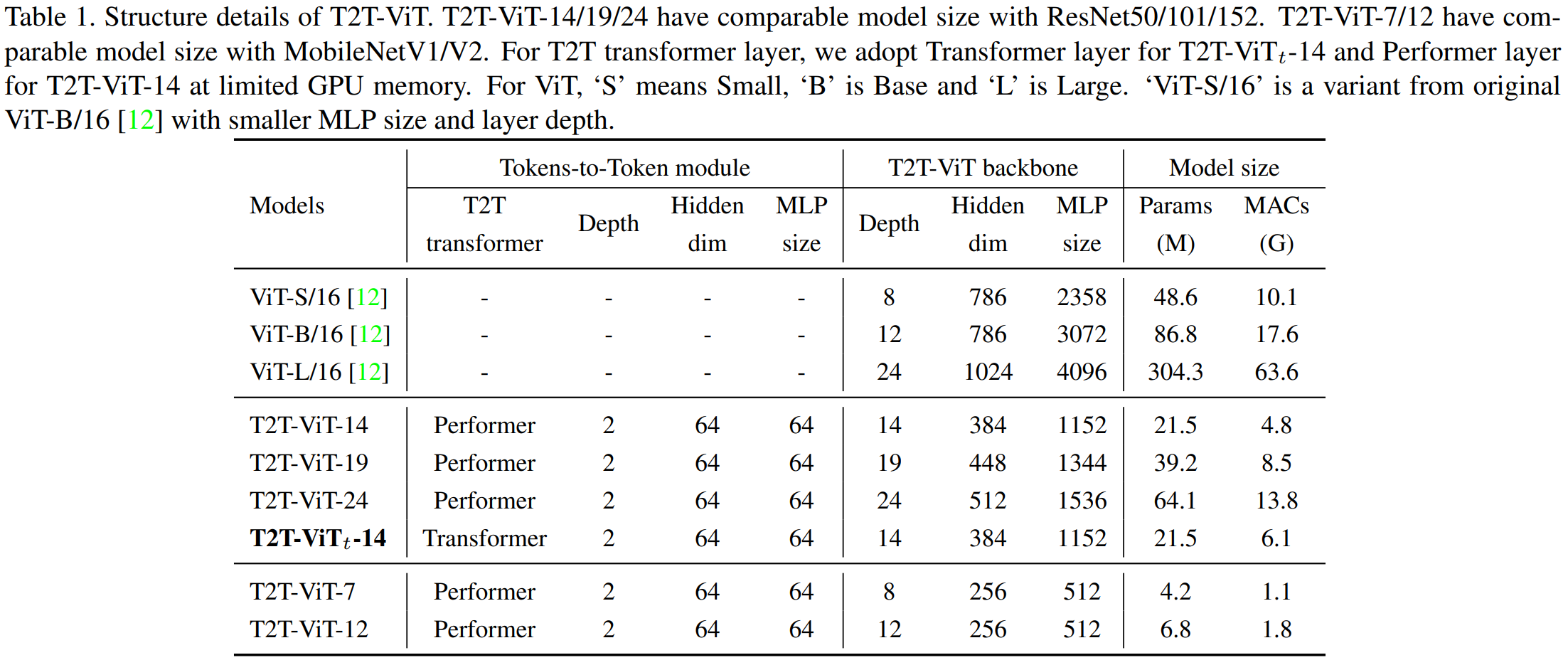
- T2T-ViT는 T2T module과 T2T-ViT backbone으로 이루어져있다.
- Fig. 4에서 나오는 n=2 (안 나와있는데... n=2가 나와있다고 적혀있다... 아마 Depth를 말하는 듯하다.) 라는 것은 맨 처음 Soft Split을 포함함 n + 1 = 3와 re-structurization n=2를 의미한다.
- Patch size(P) = [7, 3, 3]와 Stride(S) = [3, 1, 1]를 적용하여 input image 사이즈 224x224를 14x14로 줄였다고 한다.
vit_pytorch에서는 P = [7, 3, 3], S = [4, 2, 2]를 기본값으로 지정하였으며 Padding은 Stride//2로 계산하였다. 또한 T2T Transformer로 Transformer layer를 기본으로 사용하였고 Depth, Head 모두 1을 고정값으로 사용한다.- T2T-ViT에 있는 코드가 잘 작성되어있다.
728x90
'Deep Learning' 카테고리의 다른 글
| Inductive Bias (0) | 2022.08.20 |
|---|---|
| [Paper] Next-ViT: Next Generation Vision Transformer for Efficient Deployment inRealistic Industrial Scenarios (0) | 2022.08.15 |
| [Paper] Rethinking Attention with Performers (0) | 2022.08.09 |
| [Optimization] APEX ASP (Automatic SParsity) (0) | 2022.07.30 |
| The Positional Encoding (0) | 2022.03.09 |