728x90
A Dual-Stage Attention-Based Recurrent Neural Network (DA-RNN)
Instroduction

- encoder-decoder networks의 문제는 sequence의 길이가 길어질수록 성능이 낮아지는 것이다.

- 위 문제를 해결하기 위해 attention based encoder-decoder network를 사용
- 하지만 time series prediction task에는 맞지 않음

- time series prediction task를 목적으로 하는 모델인 dual-stage attnetion-based recurrent neural network (DA-RNN)을 제안
- 1 stage: 모든 time steps에서 이전 encoder hidden state를 참고하여 각 time step에서의 연관된 driving series를 adaptively 추출하기위해 새로운 attention mechanism을 개발
- 2 stage: temporal attention mechanism은 모든 time steps의 연관된 encoder hidden state들을 선택하여 사용

- 가장 많이 연관된 input feature들을 adaptively 선택
- long-term temporal dependency를 억제
Model
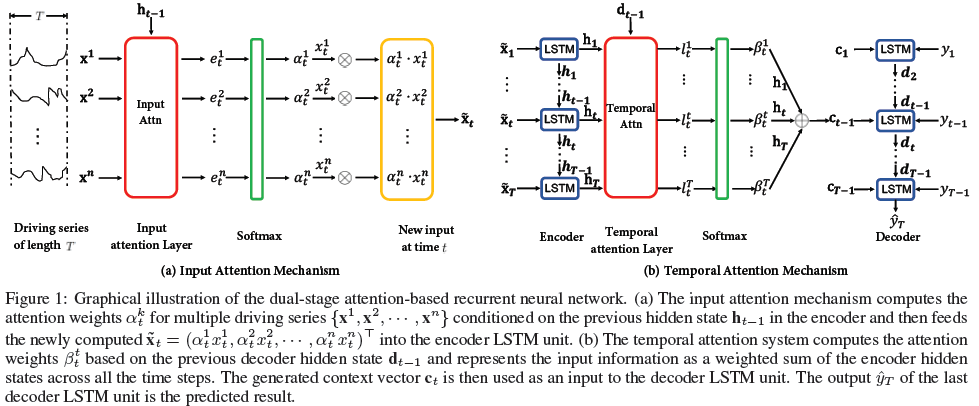
input sequence는 n개의 driving series로 이루어진 $X = (x_1, x_2, ..., x_T)$

- $h_t$: time $t$에서의 encoder의 hidden state
- $f_1$: LSTM or GRU (논문에서는 LSTM을 사용)
Input attention

- $h_{t-1}$: encoder LSTM unit에서의 previous hidden state
- $s_{t-1}$: encoder LSTM unit에서의 previous cell state
- $x^k$: k-th input driving series
Attention weights (encoder)

- $\alpha_t^k$: softmax($e_t^k$)
New input at time t

Update encoder hidden state
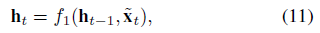
- $f_1$: LSTM
Encoder
Decoder
Temporal attention

- $d_{t-1}$: decoder LSTM unit에서의 previous hidden state
- $s'_{t-1}$: decoder LSTM unit에서의 previous cell state
- $h_i$: encoder hidden state
Attention weights (decoder)

- $\beta_t^k$: softmax($e_t^k$)
Context vector
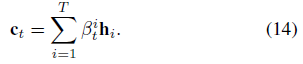
- weighted sum of all the encoder hidden states($h_i$)
New decoder input
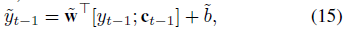
- $y_{t-1}$: decoder input (target series)
- $c_{t-1}$: computed context vector
Update decoder hidden state
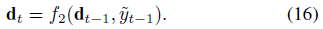
- $f_2$: LSTM
Final Prediction
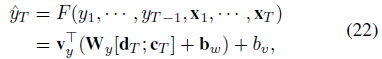
- $d_T$: decoder hidden state
- $c_T$: context vector
728x90
'Deep Learning' 카테고리의 다른 글
| [Paper] Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition (0) | 2022.03.04 |
|---|---|
| [Paper] CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition (0) | 2022.02.28 |
| [CV] Extraction Saliency Map (0) | 2022.02.18 |
| [CV&NLP] Get Model Number of Parameters (0) | 2022.02.18 |
| [NLP] Attention Mechanism (0) | 2022.02.08 |