ERD
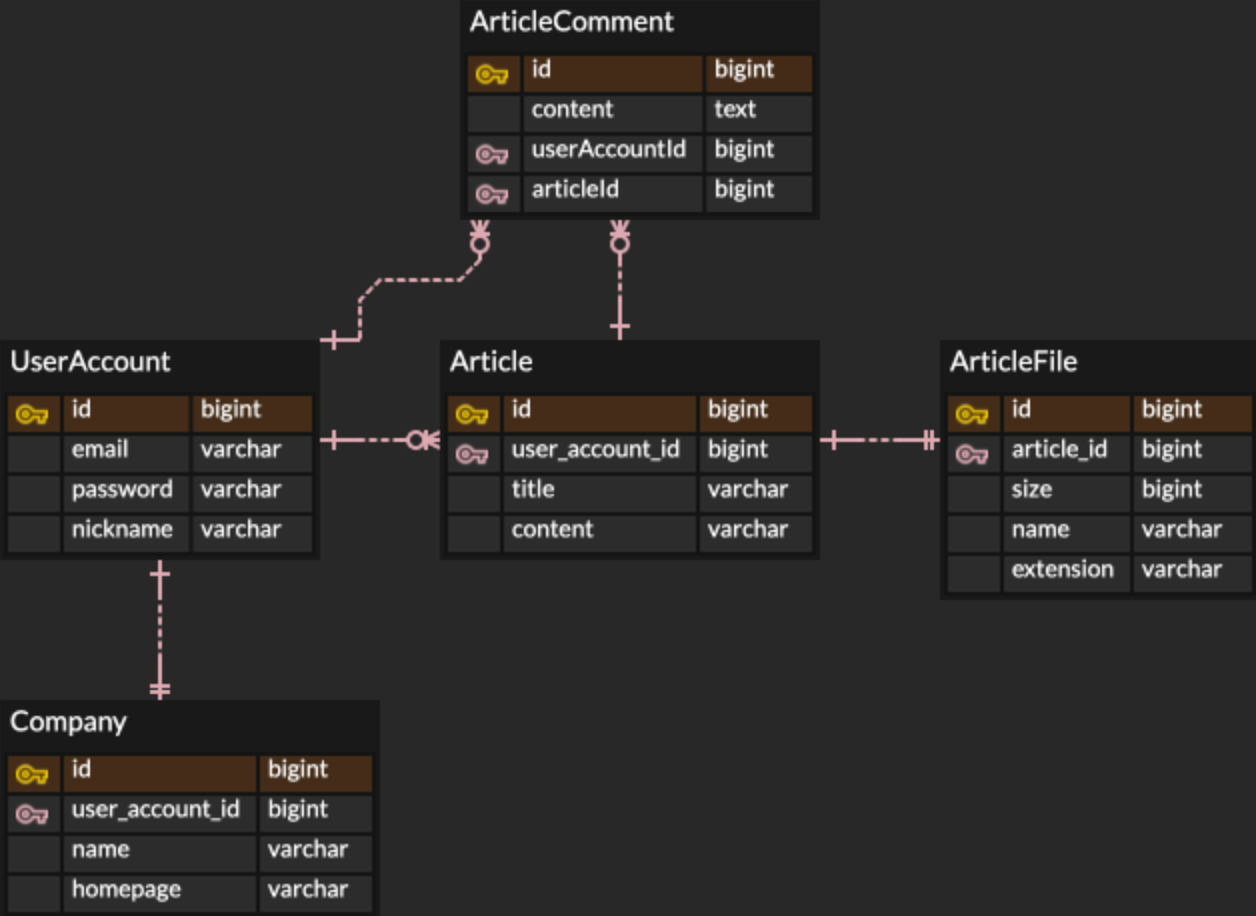
간단하게 위와 같은 구조의 DB를 가지고 있다고 했을 때 Article을 조회하면 UserAccount, ArticleComment, ArticleFile 정보가 필요하므로 같이 조회해야한다. 이때 UserAccount, ArticleFile은 1:1관계이기 때문에 조회한 Article 개수대로 결과가 반환되지만 ArticleComment는 1:N 관계로 ArticleComment 개수만큼 Article이 중복되어 결과가 반환된다.
예를 들어 ArticleComment가 100개가 있는 Article을 left join하여 조회한 결과를 보면 다음처럼 100개만큼 Article 데이터가 중복되어 나타난다.
select a.id, a.title, ac.id
from article a
left outer join article_comment ac on a.id = ac.article_id
where a.id = 3;
Join Fetch
먼저 연관된 객체들을 모두 같이 조회하기위해 다음과 같이 JPQL을 작성할 수 있다.
@Query(
"select a " +
"from Article a " +
"left outer join fetch a.userAccount " +
"left outer join fetch a.articleFile " +
"left outer join fetch a.articleComments " +
"where a.id = ?1"
)
List<Article> findByIdFetchDetail(Long id);그리고 결과를 확인해보면 SQL을 날렸던 위의 결과처럼 100개의 Article 객체가 반환되는 것을 확인할 수 있다.

중복 데이터 제거
위처럼 Article 데이터가 중복되어 출력되는 것처럼 중복된 attribute(column)을 제거하기위해서 distinct 키워드를 사용할 수 있다.
@Query(
"select distinct a " +
"from Article a " +
"left outer join fetch a.userAccount ua " +
"left outer join fetch a.articleFile af " +
"left outer join fetch a.articleComments ac " +
"where a.id = ?1"
)
List<Article> findByIdFetchDetail(Long id);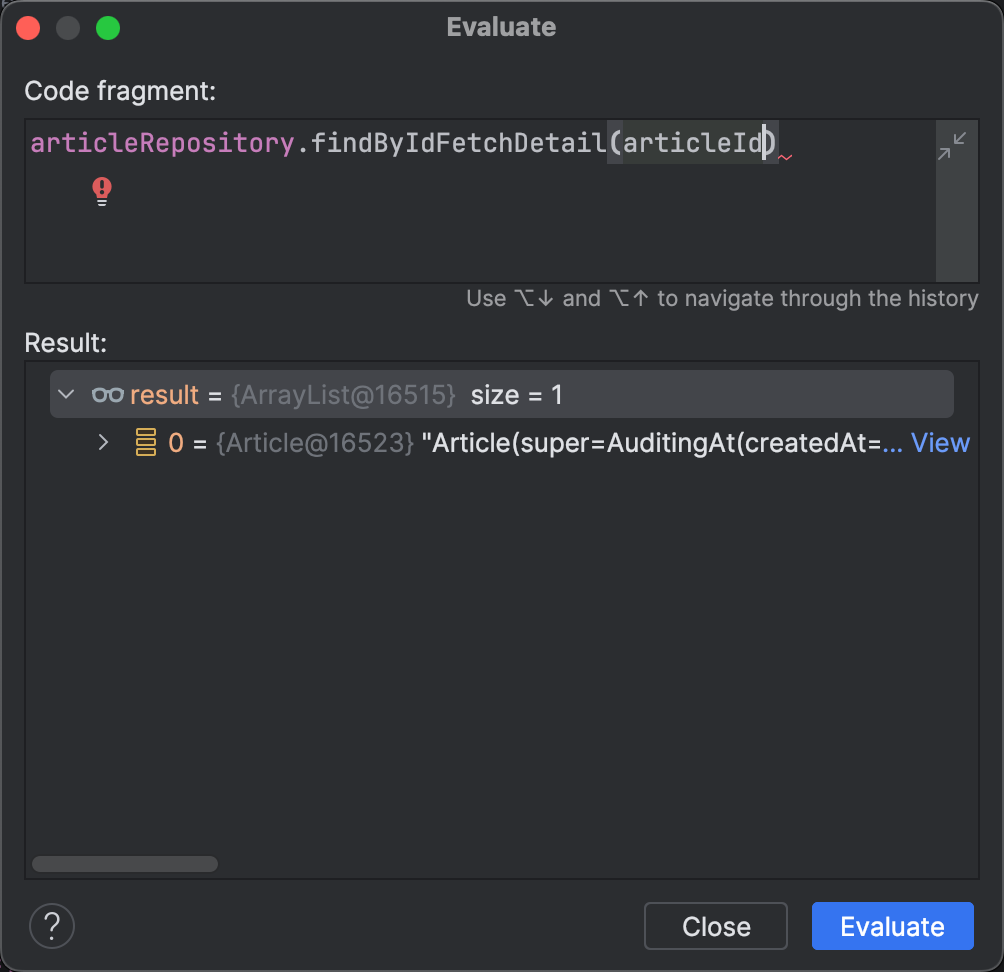
또 다른 방법으로 EntityGraph를 사용할 수 있다.
@EntityGraph(attributePaths = {"userAccount", "articleFile", "articleComments"})
@Query("select a from Article a where a.id = ?1")
List<Article> findByIdFetchDetail(Long id);EntityGraph는 default로 distinct가 적용된다고 한다. 자세한 내용은 reference에 남긴 stackoverflow 링크를 통해 확인하자.