Implicit concept detection
Sketch encoding
sketch S는 $\mathbb L^0$ primitives와 constraint의 sequence로 나열될 수 있다. 각 $\mathbb L^0$인 instance $t^0$는 type, parameter, reference의 list로 나누어진다. 그리고 각 token category는 특정 embedding module이 사용된다.
예를들어 paramter가 scalar 값인 경우 vector로 embedding되기 전에 finite bin으로 quantization 된다. (angle: 30 bins, length: 20 bins, coordinate: 80 bins)
# https://github.com/yyuezhi/SketchConcept/blob/main/data.py
self.length_quantization = 20
self.angle_quantization = 30
self.coordinate_quantization = 80
def length_quantitize(self,num): #length range [0,2]
return int((num%2)/2.00001 * self.length_quantization)
def angle_quantitize(self,num):
return int((num%(2*math.pi))/((2*math.pi)+1e-6) * self.angle_quantization)
def coordinate_quantitize(self,num): #coordinate range [-1,1]
return int(((num+1)%2)/2.00001 * self.coordinate_quantization)그리고 각 primitive는 최대 5개의 paramter(아마도 construction, length, angle, ref, coord를 말하는 것 같음)를 가지며 모든 parameter embedding을 하나로 packing한다.
# https://github.com/yyuezhi/SketchConcept/blob/main/data.py
for entity_idx, entity_key in enumerate(GT_sketch.entities):
entity = GT_sketch.entities[entity_key]
if type(entity) == Line:
primitive_parameter = [entity.isConstruction, self.coordinate_quantitize(entity.start_point[0]), self.coordinate_quantitize(entity.start_point[1]),self.coordinate_quantitize(entity.end_point[0]),self.coordinate_quantitize(entity.end_point[1])]
elif type(entity) == Circle:
primitive_parameter = [entity.isConstruction, self.coordinate_quantitize(entity.xCenter), self.coordinate_quantitize(entity.yCenter),self.length_quantitize(entity.radius)]
elif type(entity) == Point:
primitive_parameter = [entity.isConstruction, self.coordinate_quantitize(entity.x), self.coordinate_quantitize(entity.y)]
elif type(entity) == Arc:
primitive_parameter = [entity.isConstruction, self.coordinate_quantitize(entity.xCenter), self.coordinate_quantitize(entity.yCenter), self.length_quantitize(entity.radius),self.angle_quantitize(entity.startParam),self.angle_quantitize(entity.endParam)]
batch_primitive_parameter_GT_list.append(torch.tensor(primitive_parameter,dtype=torch.int64))
batch_primitive_parameter_GT = torch.nn.utils.rnn.pad_sequence(batch_primitive_parameter_GT_list,padding_value= - 1)
batch_prim_param_GT = torch.cat([batch_primitive_parameter_GT,torch.ones(6- batch_primitive_parameter_GT.shape[0],batch_primitive_parameter_GT.shape[1],dtype = torch.int64) * -1 ],dim=0).transpose(0,1)반면에 primitive index로된 각 constraint reference는 바로 embedding 된다.
따라서 $\mathbb L^0$ instance의 각 토큰은 다음과 같이 인코딩된다.
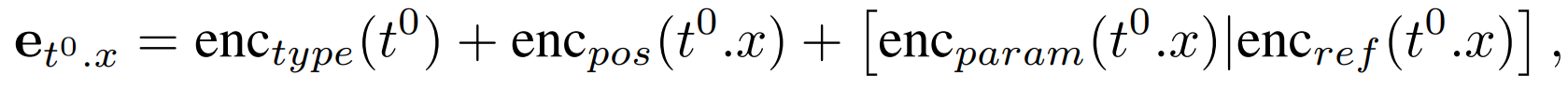
- $t^0.x$는 나누어진 token들(type, parameter, ref)의 iteration
- type embedding은 instance의 모든 token들에 공유
- position embedding는 tokenize된 전체 index를 count
- parameter, reference는 해당하는 곳에 적용
#below embedding are hardcode embedding parameter group for encoder input!
#leave it there first
self.type_embedding = nn.Embedding(self.schema_length+3, self.detection_embedding_dim).to(self.device) #4 primitive + 15 constraint + 3(start, new, end) token
self.posi_embedding = nn.Embedding(self.global_posi_max_length * self.local_posi_max_length+1, self.detection_embedding_dim).to(self.device) #max 10 attributes
self.reference_embedding = nn.Embedding(51 , self.detection_embedding_dim).to(self.device)[reference]
https://github.com/yyuezhi/SketchConcept/blob/main/model_embedding.py
Sketch encoding format
- sketch S는 $\mathbb L^0$ primitive token과 constraint token의 sequence로 인코딩
각 token은 각 indice에 따라 position encoding이 학습됨 - sequence의 앞, sequence의 끝, 인코딩된 primitive/constraint 각각의 사이사이에 학습 가능한 START, END, NEW 토큰을 추가 (19 = start, 20 = new, 21 = end)

- 각 primitive는 $\mathbb L^0$와 parameter token으로 표현
- $\mathbb L^0$의 primitive는 $enc_{type}$으로 표현된 embedding layer에 통과하여 256-dim embedding을 얻음
- primitive의 parameter는 18 tokens로 concatenation되어있며 각 token은 14-dim이고 256-dim의 zero-padding된 형태이다. 특정 primitive type에 대해서는 해당하는 type의 token들만 사용하고 나머지는 0으로 reset한다. constraint paramter를 위한 slot은 할당하지 않았다고 한다.
* dataset의 __getitem__ 에서는 -1 padding을 주었다.
- 각 constraint는 type token과 여러 reference token으로 표현
- constraint type token은 primitive에서 사용했던 embedding layer $enc_{type}$을 통해 얻음
- reference를 encoding하기 위해서는 $enc_{ref}$로 얻은 256-dim embedding을 사용
[reference]
Concept detection
encoder-decoder transformer 구조를 사용하여 detection network를 만듬
- encoder는 encoding된 sketch sequence($e_{e_i^0}$)를 통과시켜 $e_{e_i^0}^{\prime}$을 얻음
- decoder는 concept query $\bar{q}_i$ + $\bar{q}_R$을 받고 $e_{e_i^0}^{\prime}$을 self-attention, cross-attention을 통과시고 마지막으로 feed-forward layer를 통과시켜 implicit concept code $q_i$와 $q_R$을 얻음
- concept code들은 explicit 형태로 확장하기 전에 library $L^1$에서 concept prototype을 선정하여 $q_i^{\prime}$으로 quantization
# https://github.com/yyuezhi/SketchConcept/blob/main/model.py
detection_encoder_layer = TransformerEncoderLayer(self.detection_dim, self.nhead, specs_arch["feedforward_dim"],
specs_arch["dropout"], specs_arch["activation"], self.normalize_before)
detection_encoder_norm = nn.LayerNorm(self.detection_dim) if self.normalize_before else None
self.detection_encoder = TransformerEncoder(detection_encoder_layer, specs_arch["num_encoder_layers"], detection_encoder_norm)
# forward
def code_split(self,code):
""" p_i, p_R """
return [code[:,:self.max_detection_query],code[:,-1:]]
memory = self.detection_encoder(batch_tensor, src_key_padding_mask=pad_mask, pos=batch_posi) #memory [S0,B,E]
detection_output = self.detection_decoder(tgt, memory, memory_key_padding_mask=pad_mask, query_pos=detection_query,pos=batch_posi) #detection_output [S1,B,E]
#Process FC accordingly and
detection_output = detection_output.transpose(0,1) #batch first [B,S1,E]
structual_input = self.structual_FC(detection_output) #[B,S1,E] S1: number of token detection decoder output E: embedding dimension output by FC
parameter_input = self.parameter_FC(detection_output) #[B,S1,E]
structual_input = self.code_split(structual_input)
parameter_input = self.code_split(parameter_input)
structual_one_hot, structual_selection_code, commitment_loss, step_code, selection_count = self.quantitize(structual_input[0], cad_embedding, mode_flag)Network details
detection network의 encoder/decoder는 12 layers, 8 attention heads, latent dimension 256을 가진다.
'Deep Learning' 카테고리의 다른 글
| [Paper] Discovering Design Concepts for CAD Sketches (3) (0) | 2023.05.14 |
|---|---|
| Library Induction Problem (0) | 2023.05.06 |
| [Paper] Discovering Design Concepts for CAD Sketches (1) (0) | 2023.04.29 |
| [Paper] Link Prediction Based on Graph Neural Networks (0) | 2023.04.23 |
| [Paper] Self-supervised Spatial Reasoning on Multi-View Line Drawings (0) | 2023.04.17 |