728x90
Methodology
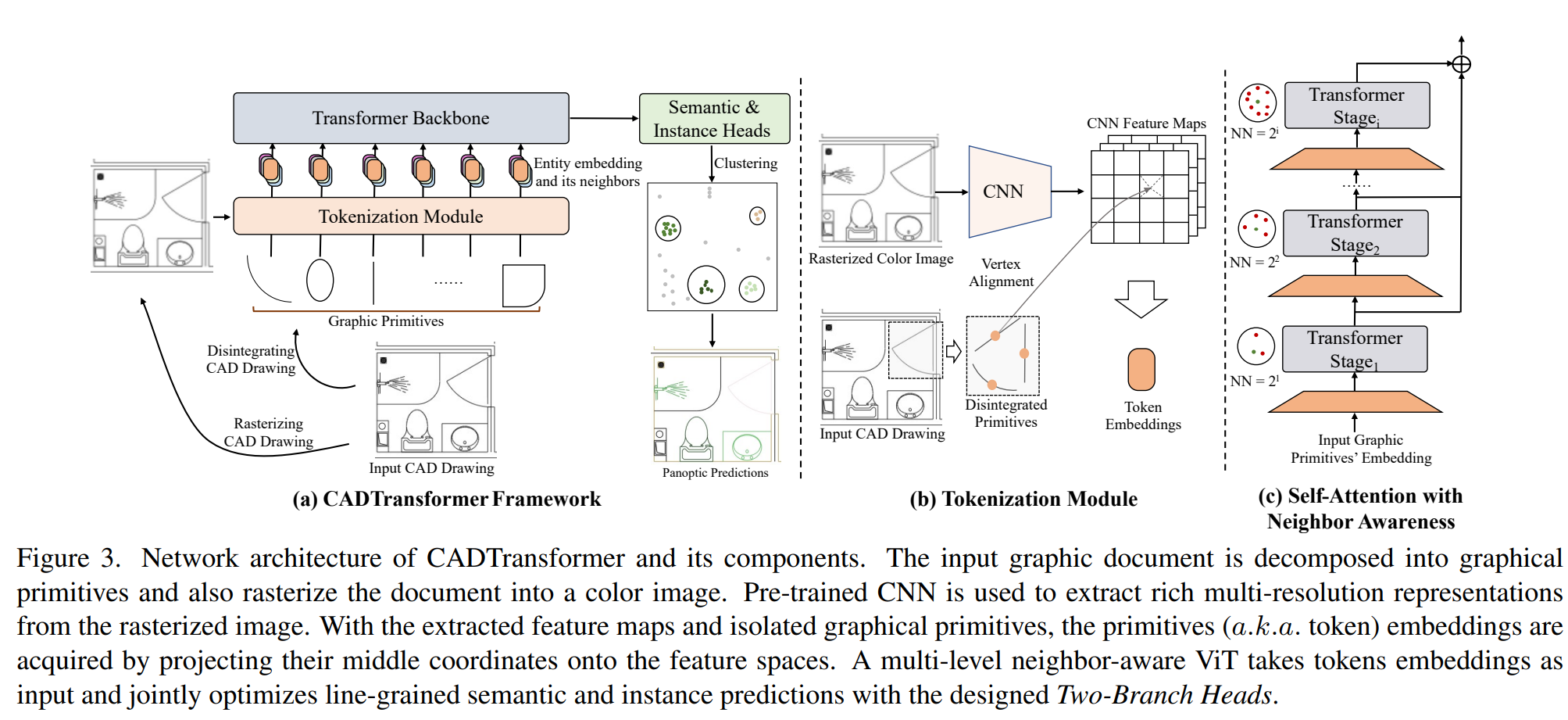
Tokenizing with Graphical Primitives
래스터 이미지에서 feature map을 추출하기위해 HRNetV2-W48 모델을 사용
- graphical primitive들(호, 선 등)로 분해
- bilinear로 feature vector를 interpolation
- primitive의 중간 위치 좌표를 feature map에 projection
Figure 3 (b)에 나타난 것처럼 feature map을 추출할 때에만 래스터 이미지를 사용하고 이외에는 CAD Drawing(vector image)을 사용한다. 또한 그림에서 vertex alignment라는 부분은 2, 3 과정이라 생각되며 코드를 확인해보면 pytorch의 grid_sample 함수로 2번 과정을 거친후 Linear 레이어를 통해 3번 과정이 수행되는 것이라 생각된다.
def vert_align_custom(feats, verts, interp_mode='bilinear',
padding_mode='zeros', align_corners=True):
if torch.is_tensor(verts):
if verts.dim() != 3:
raise ValueError("verts tensor should be 3 dimensional")
grid = verts
else:
raise ValueError(
"verts must be a tensor or have a "
+ "`points_padded' or`verts_padded` attribute."
)
grid = grid[:, None, :, :2] # (N, 1, V, 2)
if torch.is_tensor(feats):
feats = [feats]
for feat in feats:
if feat.dim() != 4:
raise ValueError("feats must have shape (N, C, H, W)")
if grid.shape[0] != feat.shape[0]:
raise ValueError("inconsistent batch dimension")
feats_sampled = []
for feat in feats:
feat_sampled = F.grid_sample(
feat,
grid,
mode=interp_mode,
padding_mode=padding_mode,
align_corners=align_corners,
) # (N, C, 1, V)
feat_sampled = feat_sampled.squeeze(dim=2).transpose(1, 2) # (N, V, C)
feats_sampled.append(feat_sampled)
feats_sampled = torch.cat(feats_sampled, dim=2) # (N, V, sum(C))
return feats_sampled
Semantic Symbol Spotting Head
- transformer에서 얻은 feature vector로 N개의 entity의 semantic score를 계산
- CE loss를 사용하여 loss 계산
- maximum score(argmax)를 사용하여 entity의 label을 예측
Instance Symbol Spotting Head
일반적으로 detection을 수행할때 bounding box로 예측할 경우 문제가 생긴다. 예를 들어 하나의 문(door)이 있고 문의 한 쪽에 벽이 겹쳐있다면 예측된 box는 정확도가 떨어진다.
이런 문제를 해결하기위해 instance의 중심을 기준으로 주변의 entity들을 모아 entity 별 offset vector들을 예측하는 것을 제안한다. 즉, 어떤 중심이 되는 instance를 기준으로 주변 entity들의 offset vector를 예측하여 관련된 것들만 묶는다는 얘기이다.
이후 clustering (mean-shift algorithm)을 수행한다.
[reference]
https://github.com/VITA-Group/CADTransformer/blob/main/models/model.py
728x90