Introduction
기존 Transformer계열 모델은 token이 모두 고정된 scale을 가진다. semantic segmentation과 같은 vision task는 pixel level의 dense prediction을 요구하는데 이때 high-resolution image를 가지고 self-attention 연산이 이루어져서 quadratic한 연산 복잡도를 가진다.

이러한 문제를 해결하기위해 Swin Transformer를 제안한다. 이 모델은 계층적인 feature map으로 구성되고 image size에 따른 linear한 연산 복잡도를 가진다.
위 그림의 (a)를 보면, Swin Transformer는 작은 크기의 path로 시작하여 계층적인 representation을 구성하고 인접한 patch들을 merge한다. 이런 계층적인 feature map을 가짐으로써 FPN, U-Net과 같은 dense prediction을 할 수 있다. linear한 연산 복잡도는 분할된 이미지인(빨간 외곽선) non-overlapping window는 지역적으로 연산을 수행하여 가능하게 했다. 각 window에서의 patch 개수는 고정되어있으므로 복잡도가 image size에 따라 linear하다.

Swin Transformer의 중요한 요소는 Figure2처럼 연속적인 self-attention 간의 window partition을 이동시키는 것이다. 이동시킨 window는 앞의 layer에서의 window와 연결시킴으로써 modeling power를 굉장히 높일 수 있다.
Method
Overall Architecture

Self-attention in non-overlapped windows
각 window는 M x M 개의 path를 가지고 있고 global MSA module과 window MSA의 연산 복잡도는 다음과 같다.
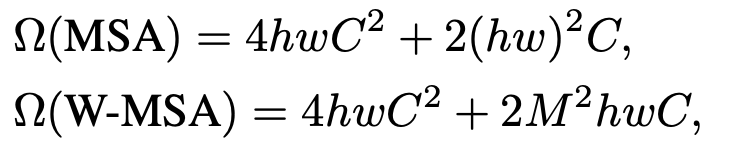
MSA의 경우 hw에 따라 quadratic하고 W-MSA는 고정된 크기 M에따라 Linear하다.
Shifted window partitioning in successive blocks
window-based self-attention module은 window간의 connection이 부족하다. non-overlapping window의 효율적인 연산과 동시에 window 간의 connection을 보완하기위해 shifted window partitioning을 제안한다.
Figure 2처럼 첫 번째 module은 좌상에 위치한 pixel에서부터 시작해서 일반적인 window partitioning을 진행하고 8 x 8 크기의 feature map은 4 x 4(M=4) 크기의 window를 가지는 2 x 2 개의 partition이된다. 그리고 다음 module은 앞단의 layer에서 shift되어 window 크기가 조정된다.
연속적인 Swin Transformer block은 다음과 같이 연산된다.

첫 번째는 Window-MSA, 이후부터는 Shifted Window-MSA로 진행되는 것을 확인 할 수 있다.
Efficient batch computation for shifted configuration
shifted window partitioning의 문제는 더 많은 window가 나올 수 있는 것과 M x M 보다 작은 window가 나올 수 있다는 것이다. 간단한 방법으로 M x M 크기 보다 작은 window는 padding을 하고 padded value로 masking하여 attention을 연산하는 것이다. 하지만 일반적인 partitioning에서 window 개수는 2x2처럼 작을 때, 이러한 방법은 연산을 증가시킨다.
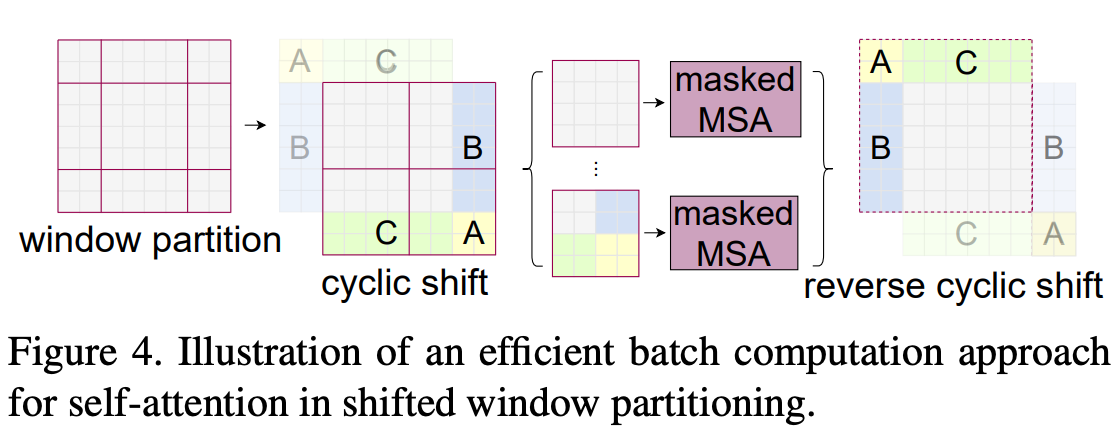
그래서 Figure 4처럼 top-left 방향으로 cyclic-shifting을 하는 more efficient batch computation approach를 제안한다. shift를 하고 window는 여러 개로 구성된 sub-window들(A, B, C)은 원래 feature map에 붙어있는 것이 아니기때문에 각 sub-window들끼리 self-attention을 수행하지 못하게 masking을 해버린다. masking 연산을 수행한 후에는 reverse cyclic shift를 통해 원래 값으로 되돌린다.
Relative position bias

Swin Transformer에서는 위처럼 relative position bias(B)를 더해서 self-attention을 계산하다. absolute position embedding을 추가하는 것보다 좋은 성능을 보였다고 한다.
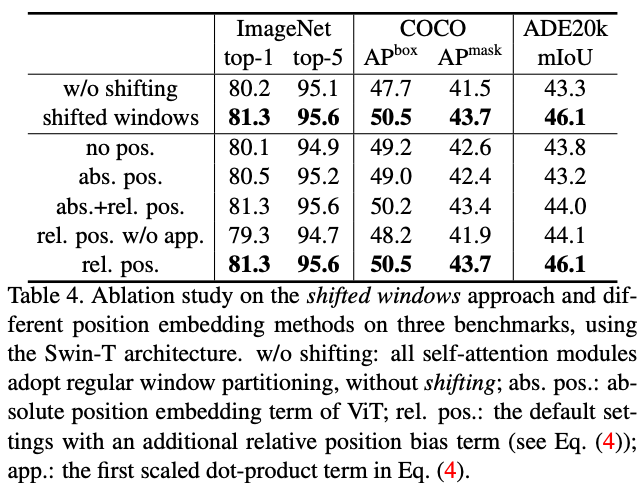
아마 shift를 한다는 점에서 relative가 당연 적합했었을 것 같다.
'Deep Learning' 카테고리의 다른 글
| [Paper] Automated 3D solid reconstruction from 2D CAD using OpenCV (1) (0) | 2023.01.02 |
|---|---|
| [Paper] Separable Self-attention for Mobile VisionTransformers (0) | 2022.12.26 |
| Panoptic segmentation (UPSNet, VPSNet)와 Landmark Localization (0) | 2022.11.14 |
| Instance Segmentation (Mask R-CNN, YOLACT, YolactEdge) (0) | 2022.11.14 |
| Semantic Segmentation (U-Net, DeepLab) (0) | 2022.11.14 |