Instance segmentation

instance segmentation은 위 그림처럼 같은 클래스라도 instance가 다르면 구분을 해준다.
- Mask R-CNN
Fast R-CNN에서는 RPN(region proposal network)에 의해 나온 bounding box에 RoI Pooling을 사용하였다. 그리고 기존 RoI Pooling은 정수 좌표밖에 지원하였다. 하지만 Mask R-CNN에서는 RoIAlign이라는 새로운 Pooling layer를 제안하였고 RoIAlign에서는 interpolation을 통해서 소수점 픽셀 level의 pooling을 지원하게 되었다. 따라서 더욱 정교한 feature를 뽑을 수 있게 되고 그 뒷단의 성능이 향상되는 것으로 이어진다.
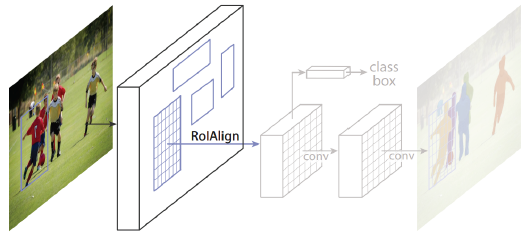
그리고 Fast R-CNN에서는 pooling된 feature 위에 올라가있던 Classifiaction과 box regression이 있었다. Mask R-CNN에서는 좀 더 확대해서보면 Mask branch가 있는데 아래 그림처럼 7x7에서 14x14로 upsampling을 하고 channel을 2048에서 256으로 줄인다. 그 다음 각 클래스별로 binary mask를 prediction하는 구조를 가지고 있다. 다시 말해 모든 클래스에 대해 mask를 생성하고 classification head에서 class 정보가 모일 것이라는 예측 결과를 이용하여 어떤 mask를 참조할 것인지 선택하는 것이다.

- YOLACT (You Only Look At CoefficienTs)
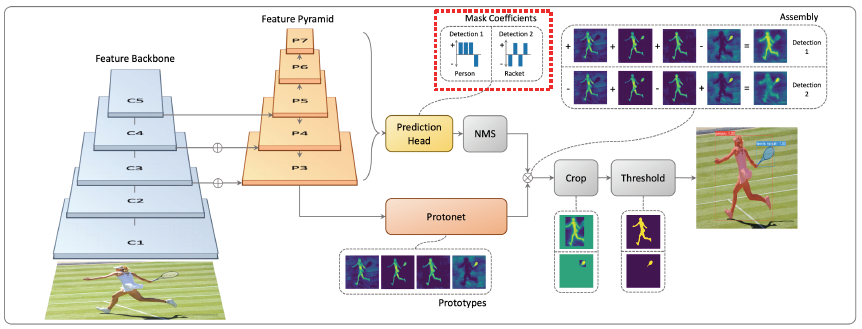
YOLACT 는 real-time으로 segmentation이 가능한 single stage network이다. 기본 backbone구조는 feature pyramid 구조를 가지고 와서 사용한다. 고해상도의 feature map을 가지고 사용을 할 수 있게되는데 가장 큰 특징은 mask의 prototype을 추출해서 사용한다는 것이다. Mask R-CNN에서는 실제로 사용하지 않더라도 80개의 class를 고려하고 있다고 한다면 80개의 각각 독립적인 mask를 한 번에 생성해내었다. 그중에서 classification된 결과에 따라서 하나를 참조하는 형태였다. 하지만 여기에서는 prototype이라고해서 mask는 아니지만 mask를 합성해낼 수 있는 기본적인 여러 물체의 soft segmentaion component들을 생성한다. 여기까지는 mask는 아니지만 mask로 합성될 수 있는 재료를 제공한다고 이해하면 된다.
prediction head에서 각 detection에 대해서 prototype들을 잘 합성하기 위한 계수들을 출력해준다. 그리고 이 계수들과 prototype을 선형 결합하여 각 detection에 적합한 mask response map을 생성해준다.
여기서 key point는 prototype의 수를 object의 수와 상관없이 작게 설정하여 선형 결합을 통해 다양한 mask를 생성하는 것이다. 만약 prototype의 수를 object의 수로 설정한다면 더 많은 비용이 발생할 것이기 때문이다.
- YolactEdge
이전 keyframe에 해당하는 feature를 다음 frame에 전달해서 feature map의 계산량을 획기적으로 줄였다. 또한 성능은 기존 방법과 유지할 수 있는 방법을 제시하였다.

'Deep Learning' 카테고리의 다른 글
| [Paper] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2022.11.16 |
|---|---|
| Panoptic segmentation (UPSNet, VPSNet)와 Landmark Localization (0) | 2022.11.14 |
| Semantic Segmentation (U-Net, DeepLab) (0) | 2022.11.14 |
| LSTM (Long Short Term Memory)과 GRU(Gated Recurrent Unit) (0) | 2022.11.14 |
| Object Detection (R-CNN, SPPNet, Fast-RCNN, Faster-RCNN, YOLO) (0) | 2022.11.14 |