728x90
일반 객체 영역 검출 vs 글자 영역 검출
- 일반 객체 검출 : 클래스와 위치를 예측
- 글자 검출 : "Text"라는 단일 클래스 위치만 예측
- 객체의 특징
- 매우 높은 밀도
- 극단적 종횡비
- 특이 모양 : 구겨진 영역, 휘어진 영역, 세로 쓰기 영역, 모호한 객체 영역, 크기 편차
- 사각형 종류
- 직사각형 : (x1, y1, width, height), (x1, y1, x2, y2)
- 직사각형 + 각도 : (x1, y1, width, height, $\theta$), (x1, y1, x2, y2, $\theta$)
- 사각형 : (x1, y1, ... , x4, y4)
- 다각형
- Arbitrary-shaped text를 주로 다루는 최근의 벤치마크들에 적합
- 일반적으로 2N points를 이용하고, 상하 점들이 쌍을 이루도록 배치
Regression-based vs Segmentation-based
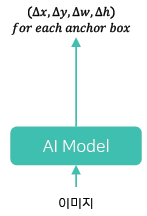
- Regression-based : 이미지를 입력 받아 글자 영역 표현값들을 바로 출력
- Arbitary-shaped text : 불필요한 영역을 포함
- Extreme aspect ratio : Bounding box 정확도 하락
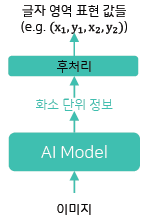
- Segmentation-based : 이미지를 입력 받아 글자 영역 표현값들에 사용되는 화소 단위 정보를 뽑고 후처리를 통해서 최종 글자 영역 표현 값들을 확보
- 복잡하고 시간이 오래 걸리는 후처리가 필요할 수 있음
- 서로 간섭이 있거나 인접한 개체 간의 구분이 어려움
Character-based vs Word-based

- Character-Based Methods
- Character 단위로 검출하고 이를 조합해서 word instance를 예측
- Character-level GT 필요

- Word-Based Methods
- Word 단위로 예측
- 대부분의 모델이 해당
EAST (An Efficient and Accurate Scene Text Detector)
- 단순한 파이프라인을 구조를 가져서 속도도 빠르고 성능도 좋은 모델

- EAST는 일종의 Segmentation 기반의 방법으로 AI 모델을 통해서 화소 단위의 정보를 뽑고 후처리를 해서 글자 영역을 검출한다.
- 화소 정보로는 글자 영역이 중심에 해당하는지에 대한 score map, 어떤 화소가 글자 영역이라면 해당 bounding box의 위치가 어디인지에 대한 geometry map
- score map일 경우 영역 내 중심에 해당하는 지를 나타내고 geometry map의 경우 어떤 화소가 글자 영역 내에 있으면 해당 bounding box의 위치에 대한 정보를 나타냄
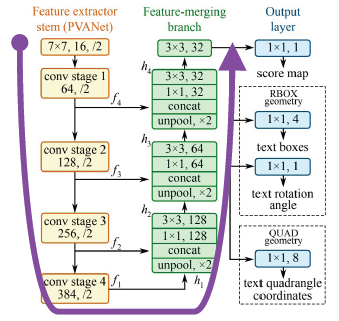
- 전체 구조를 보면 segmentation에서 많이 활용되는 unet구조를 띔
- unet은 의료 영상 분석 task에서 처음 등장한 후 segmentation task에서 많이 사용되는 모델
- 크게 세 가지 부분으로 구성되어 있음
- Feature extractor stem (backbone)
- PVANet, VGGNet, ResNet50
- Feature merging branch : feature map을 키워가며 여러 level들을 합쳐줌
- Unpool로 크기 맞추고 concat
- 1x1, 3x3 convolution으로 channel 수 조절
- Output : 화소 단위의 정보를 만듬
- H/4 x W/4 x C maps
- Feature extractor stem (backbone)
Score Map
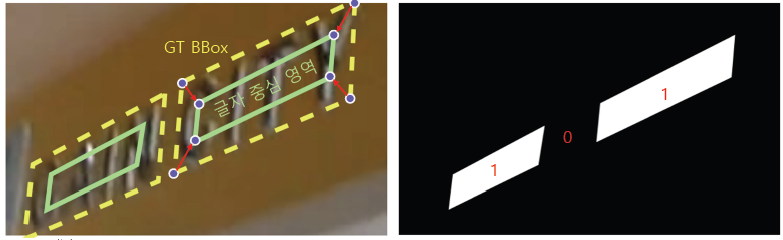
- 이미지 크기가 가로 세로 별로 1/4로 축소된 크기의 binary map
- binary map인 이유는 1의 값이면 글자 영역의 중심, 배경이면 0인 것을 표현하기 위함
- 정답을 만들어낼 때는 GT Bounding box에서 중앙으로 영역을 줄여서 글자 중심 영역을 만들고 이진 값으로 채움
- 추론할 경우에는 score map을 예측할 때 0과 1 사이의 실수 값이 나오도록하여 글자 영역 중심에 속할 확률로 해석함
Geometry Map


- 어떤 화소가 글자 영역이라면 해당 bounding box의 위치가 어디인지를 나타내는 정보
- RBOX
- 만약 글자 영역을 RBOX로 표현한다면 각도 정보를 나타내는 1 채널과 직사각형에 대한 4 채널을 사용
- 각도 값의 경우 글자 중심 영역에 모든 화소와 연관되어 있는 bounding box는 하나이고 그 각도값을 $\theta$ 값이라 할 수 있다. 그래서 각도 값에 대한 채널은 글자 중심 영역에 대해서 동일한 각도 값으로 채울 수 있다.
- 직사각형 정보에 대한 경우 첫 번째 채널은 글자 중심 영역의 어떤 화소에서 해당 bounding box에 좌변까지의 거리 값을 채울 수 있다. 그러면 좌변에서 멀어질수록 큰 값을 가지게 된다. 유사하게 두 번째 채널은 글자 중심 영역에서 bounding box의 우변까지의 거리 값으로 채우고 세 번째 채널은 글자 중심 영역에서 bounding box의 상변까지의 거리 값으로 채우로 네 번째 채널은 하변까지의 거리 값으로 채운다.
- 글자 중심 영역의 화소 위치에서 5개의 채널에 해당하는 값을 채워넣는데 하나는 각도 값, 나머지 4개는 bounding box 까지의 거리 값으로 채워넣는다.
- QUAD
- 임의의 사각형 좌표 4개로 글자 영역을 표현할 때 8개의 채널을 사용
- 첫 두 채널은 bounding box 첫 번째 좌표까지의 좌표 값의 차이를 x, y별로 따로 계산하여 채운다. 유사하게 나머지 채널들도 채운다.
Post-processing(RBOX 기준)
- Score Map을 임계치를 통해서 이진화를 한다. 1의 값을 가진 위치는 글자 영역 중심이라고 판단할 수 있음
- 사각형 좌표값을 복원해야한다. 우리가 알고 있는 것은 좌표 o에서 직사각형까지의 거리 값인 d0~d3까지와 각도 값이다. 이를 바탕으로 p0~p3 4개의 좌표를 알아내야한다.
- p0~p3의 좌표를 쉽게 구할 수 있는 좌표 축을 새로 설정
- 좌표축을 이미지 좌표축으로 변환하는 과정을 구함
- 이 변환의 역변환을 좌표값들에 적용
- 글자 중심 영역 좌표 하나당 예측 bouding box 하나가 나오게 되면 실제 예측 결과는 글자 중심 영역 내 화소별로 다 구하므로 많은 bounding box들이 나온다. 이를 합쳐주기 위한 작업으로 Non-Maximum Suppression을 사용한다. 하지만 box가 너무 많으면 연산량이 많아지기 때문에 새로운 방식인 Locality-aware NMS를 사용한다.

- Locality-aware NMS : IoU가 높은 bounding box들이 많으므로 이를 빠르게 합치고 이후에 기존의 NMS를 적용
Loss Term(RBOX 기준)
- 전체 loss function = loss for score map + loss for geometry map
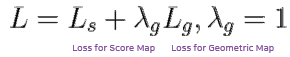
- Ls : Score map loss
- 논문에서는 Class-balanced cross-entropy를 사용

- 코드에서는 Dice-coefficient를 사용
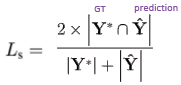
- Lg : Geometry map loss
- 사각형에 해당하는 loss 값과 각도 값에 해당하는 loss 값으로 최종 loss 값을 계산

- 사각형의 정보에 해당하는 loss 값은 정답 사각 영역과 예측 사각 영역에대한 loss 값이 되고 IoU 기반의 계산식으로 실제 계산이 이루어진다. 이 때 분모에서 두 사각 영역의 합집합에 대한 절대값을 구하여야하는데 교집합에 대한 절대값과 각 영역에 대한 절대값을 통해서 계산이 가능하다.
- 각도 값에 대한 loss의 경우 cosine 기반의 loss 값을 사용한다.
F-score & Speed
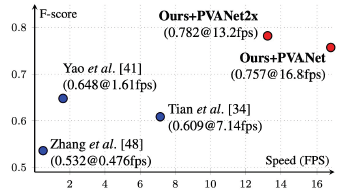
- Real-time 수준은 아니지만 초당 17장 처리정도의 빠른 속도를 가짐
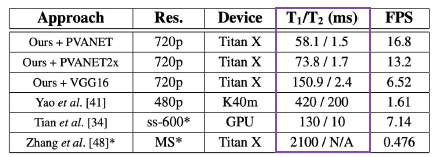
- 추론 속도는 네트워크 계산 시간인 T1과 후처리(NMS) 시간의 합인데 논문에서 제안한 LA-NMS를 사용한다면 T1에비해서 T2는 무시해도 될 시간 정도로 나온다.
728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp 15주차] 피어세션과 학습 회고 & 실험일지 (0) | 2021.11.12 |
|---|---|
| [Boostcamp Day-65] 데이터 제작의 중요성 (0) | 2021.11.12 |
| [Boostcamp Day-67] 성능 평가 기준 (0) | 2021.11.12 |
| [Wrap-up report] Semantic Segmentation (0) | 2021.11.07 |
| [실험 일지 Day-62] Pstages - Semantic Segmentation (0) | 2021.11.06 |