728x90
DeepLab v2
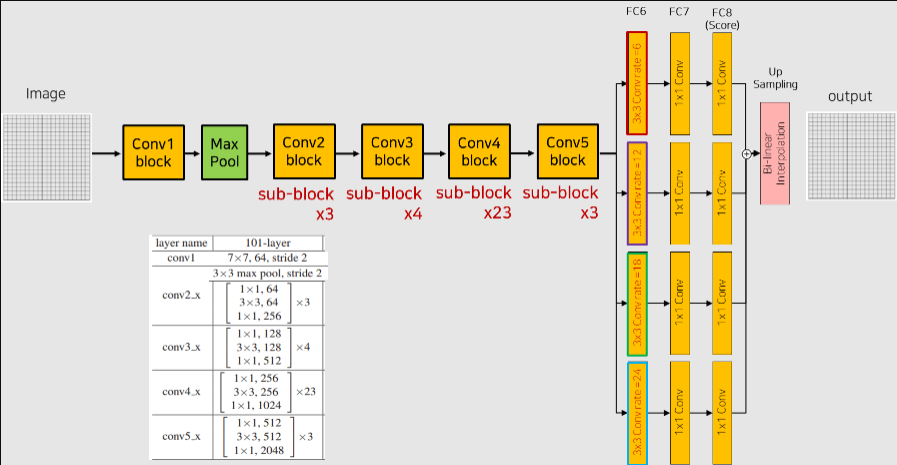
- 성능 향상을 위해 더 깊은 ResNet-101 구조 사용
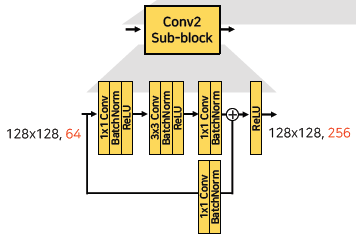
- 64 channel과 256 channel을 맞춰주기 위해 다음과 같이 구성
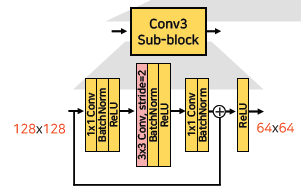
- Conv3 부터 down sampling을 수행하기위해 stride=2를 지정하고 채널을 맞추기 위해 다음과 같이 1x1 Conv를 추가한다.
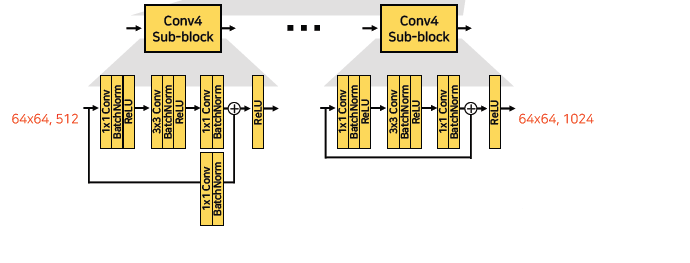
- Conv4, Conv5에서는 down sampling을 수행하지 않고 dilated convolution을 사용
- ASPP를 적용하여 다양한 크기의 receptive field를 고려
PSPNet
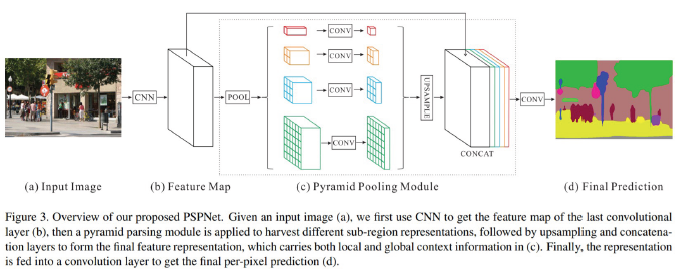
PSPNet은 1x1, 2x2, 3x3, 6x6 출력의 Average Pooling을 적용하였다.
- Global Average Pooling : 주변 정보를 파악해서 객체를 예측하는데 사용
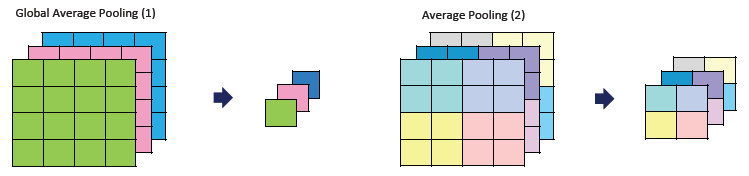
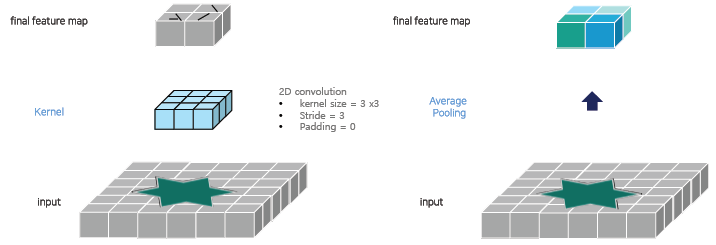
- Convolution vs Average Pooling
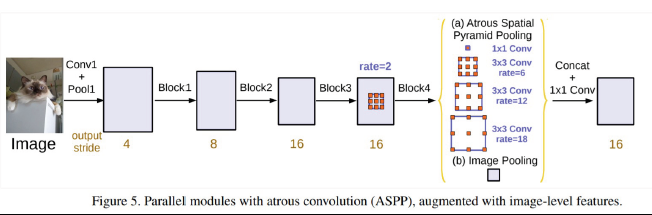
DeepLab v3
DeepLab v3+
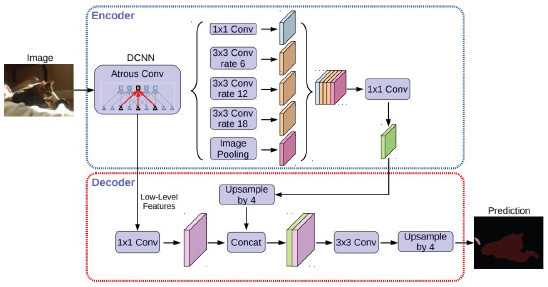
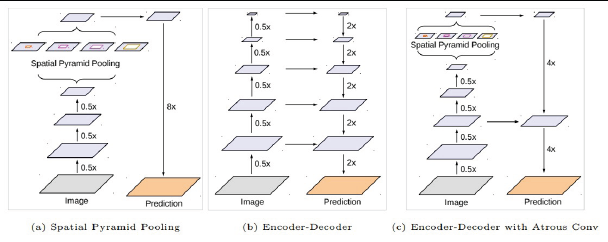
- Encoder - Decoder 구조 : Encoder에서 spatial dimension의 축소로 인해 손실된 정보를 Decoder에서 점진적으로 복원
- Encoder
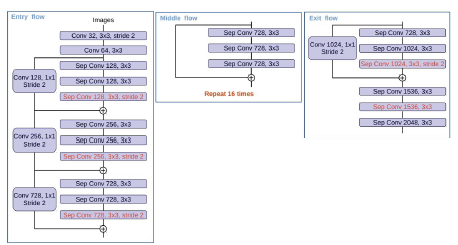
- 수정된 Xception을 backbone으로 사용
- Atrous separable convolution을 적용한 ASPP 사용
- Backbone 내 low-level featrue와 ASPP 모듈 출력을 모두 decoder에 전달
- Decoder
- ASPP 모듈의 출력을 up-sampling하여 low-level feature와 결합
- 결합된 정보는 convolution 연산 및 up-sampling 되어 최종 결과 도출
- 기존의 단순한 up-sampling 연산을 개선시켜 detail을 유지하도록 함
- Xception
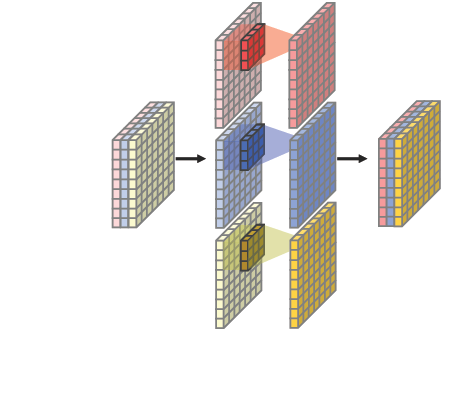
- Xception구조는 Depthwie Separable Convolution(Depthwise Convolution+Pointwise Convolution)을 사용
- Depthwise Convolution : 각 채널마다 다른 filter를 사용하여 convolution 연산 후 결합
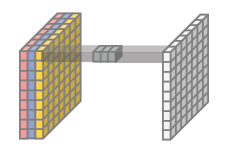
- Pointwise Convolution : 1x1 Convolution
- Modified Xception Backbone
728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp 12주차] 피어세션과 학습 회고 & 실험일지 (0) | 2021.10.22 |
|---|---|
| [Boostcamp Day-53] U-Net (0) | 2021.10.22 |
| [Boostcamp Day-51] FCN의 한계를 극복한 model 1 (0) | 2021.10.22 |
| [Boostcamp Day-50] Competition Overview (0) | 2021.10.22 |
| [Wrap-up report] Object Detection (0) | 2021.10.17 |