728x90
Detector의 디자인 고려사항
- 작은 물체 검출하기 위해 큰 네트워크 입력 사이즈 필요
- 네트워크 입력 사이즈가 증가함으로서 큰 receptive field 필요 -> 많은 layer를 필요
- 하나의 이미지로 다양한 사이즈의 물체 검출하기 위해 모델의 용량이 더 커야함 -> 많은 파라미터 필요
YOLO v4

1. Cross Stage Partial Network (CSPNet)
- 정확도 유지하면서 경량화
- 메모리 cost 감소
- 다양한 backbone에서 사용가능
- 연산 bottleneck 제거
2. Additional Improvements
- Data Augmentation
- Mosaic
- Self-Adversarial Training

- Modified Spatial Attention Module
- Modified Path Aggregation Network
- Cross Mini-Batch Normalization


M2Det
- Multi-level, Multi-scale feature pyramid 제안 (MLFPN)
- SSP에 합쳐서 M2Det이라는 one stage detector 제안
- 8개의 TUM 사용
- 출력 : 6개의 scale features
- Detection Stage
- 6개의 feature마다 2개의 convolution layer 추가해서 regression, classification 수행
- 6개의 anchor box 사용
- Soft-NMS 사용

1. Feature Fusion Module(FFM) v1
- FFM v1 : base feature 생성
- Base feature : 서로 다른 scale의 2 feature map을 합쳐 semantic 정보가 풍부함

2. Thinned U-shape Module(TUM)
- Encoder-decoder 구조

3. Feature Fusion Module(FFM) v2
- FFM v2 : base feature와 이전 TUM 출력 중에서 가장 큰 feature concat
- 합쳐준 feature는 다음 TUM의 입력으로 들어감

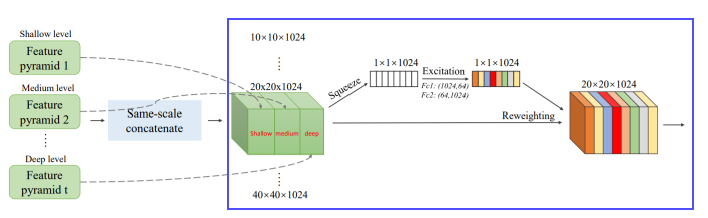
4. Scale-wise Feature Aggregation Module(SFAM)
- TUMs에서 생성된 multi-level, multi-scale을 합치는 과정
- 동일한 크기를 가진 feature 들끼리 연결 (scale-wise concatenation)
- 각각의 scale의 feature들은 multi-level 정보를 포함

- Channel-wise attention 도입 (SE block)
- 채널별 가중치를 계산하여 각각의 feature를 강화시키거나 약화시킴
5. SSD

CornerNet
- Anchor Box가 없는 one stage detector
- 좌측 상단 (top-left), 우측 하단 (bottom-right) 점을 이용하여 객체 검출
- Center(중심점)이 아니라 Corner(모서리) 사용하는 이유
- 중심점을 잡게되면 4개의 면을 고려해야하는 반면, corner를 사용하면 2개만 고려

1. Hourglass
- Human pose estimation task 에서 사용하는 모델
- Global, local 정보 모두 추출 가능
- Encoder-Decoder 구조
- Encoder : 입력으로부터 특징 추출
- Decoder : Reconstruct
- Encoding Part
- Feature 추출 : convolution layer + maxpooling layer
- 별도의 branch로 convolution 진행해서 스케일마다 feature 추출 (upsampling 과정에서 조합)
- CornerNet에서는 maxpooling 대신 stride 2 사용, 스케일 5번 감소

- Decoding part
- Encoder 과정에서 스케일별로 추출한 feature 조합
- Upsampling 과정에서는 Nearest Neighborhood Sampling, feature 조합에서는 element-wise addition 사용
2. Prediction Module

3. Detecting corner
- 2개의 heatmap을 통해서 예측 (top-left, bottom-right)
- HxWxC로 구성
- 각 채널은 클래스에 해당하는 corner의 위치를 나타내는 binary mask
- 모든 negative 위치 (location)을 동일하게 패널티 주는 것이 아님
- Positive location 반지름 안에 들어오는 negative location들은 패널티를 감소시킴
- 반지름은 물체의 크기에 따라 결정
- 거리에 따라 패널티 감소
- Focal loss 변형
- 정답에 근접한 예측값은 낮은 loss 부여

- Convolution을 통과하면서 heatmap에 floating point loss 발생
- Heatmap에서 이미지로 위치를 다시 mapping 시킬 때 차이 발생
- Offset을 사용하여 예측한 위치를 약간 조정
- Smooth L1 loss 사용
4. Grouping corner
- Top-left 코너와 bottom-right 코너의 짝을 맞춰주는 과정
- Top-left 코너와 bottom-right 코너의 임베딩값의 차이에 따라서 그룹
- embedding 값 사이의 거이가 작으면 같은 물체의 bounding box에 속함

5. Corner pooling
- 코너에는 특징적인 부분이 없음
- 코너를 결정하기 위해서 corner pooling 과정 필요
- 코너에 객체에 대한 정보를 집약시켜주는 과정

728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [주말 실험 일지 - 토] Pstages - Object Detection (0) | 2021.10.15 |
|---|---|
| [Boostcamp 10주차] 피어세션과 학습 회고 & 실험일지 (0) | 2021.10.08 |
| [주말 실험 일지_일] Object Detection (0) | 2021.10.05 |
| [주말 실험 일지_토] Object Detection (0) | 2021.10.05 |
| [Boostcamp Day-42] Object Detection - Advanced Object Detection 1 (0) | 2021.10.05 |