Data Augmentation
- Brightness Adjustment
def brightness_augmentation(img):
# numpy array img has RGB value(0~255) for each pixel
img[:, :, 0] = img[:, :, 0] + 100 # add 100 to R value
img[:, :, 1] = img[:, :, 1] + 100 # add 100 to G value
img[:, :, 2] = img[:, :, 2] + 100 # add 100 to B value
img[:, :, 0][img[:, :, 0]>255] = 255 # clip R values over 255
img[:, :, 1][img[:, :, 1]>255] = 255 # clip G values over 255
img[:, :, 2][img[:, :, 2]>255] = 255 # clip B values over 255
return img- Rotate, flip
img_rotated = cv2.rotate(image, cv.ROTATE_90_CLOCKWISE)
img_flipped = cv2.rotate(image, cv.ROTATE_180)- Crop
y_start = 500 # y pixel to start cropping
crop_y_size = 400 # cropped image's height
x_start = 300 # x pixel to start cropping
crop_x_size = 800 # cropped image's width
img_cropped = image[y_start : y_start + crop_y_size, x_start : x_start + crop_x_size, :]- Affine Transformation

rows, cols, ch = image.shape
pts1 = np.float32([50, 50], [200, 50], [50, 200])
pts2 = np.float32([10, 100], [200, 50], [100, 250])
M = cv2.getAffineTransform(pts1, pts2)
shear_img = cv2.warpAffine(image, M, (cols, rows))- CutMix

- RandAugment
sequence augmentations를 random하게 골라 가장 좋은 것을 찾는 기법
- Randomly testing augmentation policies
N개의 augmentations를 Policy라고하며 이 Policy를 random sampling하여 training시키고 evaluation을 한다.
Transfer Learning
높은 quality의 dataset은 비싸고 얻기 힘들다. 하지만 Transfer Learning을 사용하게 되면 적은 dataset으로도 유용한 training을 할 수 있다.
- Approach 1 : convolution layers는 freeze하고 마지막 FC layer를 update하여 재학습을 시키는 방법

- Approach 2 : 마지막 FC layer를 새로운 것으로 대체하고 전체 모델을 재학습 시키는 방법이고 convolution layers와 FC layer의 learning rate를 다르게 설정한다

Knowledge distillation
미리 학습된 Teacher Model의 지식을 학습이 안된 다른 작은 모델(Student Model)에 주입하며 모델 압축에 유용한 방법이다. 또한 pseudo-labeling에 사용된다.

아래는 미리 학습된 Teacher Model과 더 작은 Student Model(학습이 안된)에 data feeding을 하고 나온 출력값을 KL div.Loss를 통해 backpropagation을 수행한다. 이때 Student Model만 update하게된다. 다시 말하면 student model이 teacher model의 행동을 따라하게되는 학습법이라고 할 수 있다.

위에서는 labeling이 되지않은 data를 사용하였기 때문에 임의의 data로 학습할 수 있지만 다음과 같이 labeling된 data로 학습할 때 Ground Truth Y(one-hot)을 이용하여 student loss라고 불리는 loss를 계산, Teacher Model은 위에서 언급한 KL div.Loss와 같은 Distillation Loss를 계산한다.
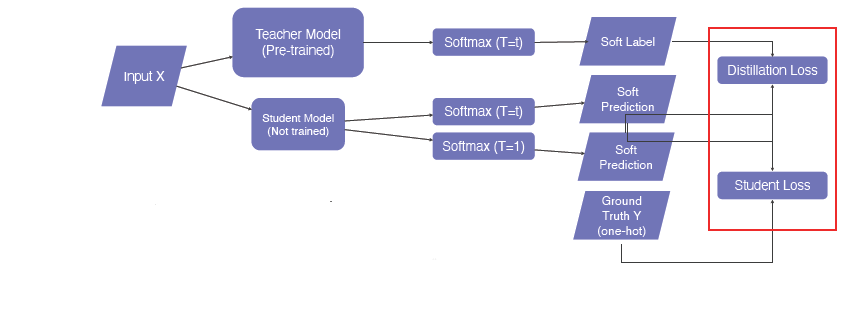
- Hard label (One-hot vector)
하나의 클래스가 true인지 아닌지를 가르킨다.
- Soft label
각 클래스별 확률 값들을 가리킨다. -> 모델이 어떻게 생각하는지를 관찰하는데 유용하다.-
- Softmax with temperature (𝑇)
일반적인 softmax은 입력값의 확률을 극단적으로 차이가 나지만 T를 사용한 soft prediction은 각 입력값의 확률을 smooth하게 중간값으로 만들어준다.

- Distillation Loss : KLdiv(Soft label, Soft prediction)
- Student Loss : CrossEntropy(Hard label, Soft prediction)
Semi-supervised learning
labeling된 dataset과 안 된 dataset을 가지고 학습하는 방법(Unsupervised (No label) + Fully Supervised (fully labeled))

pseudo labeling을 사용한 semi-supervised learning은 다음과 같다.
- labeled dataset으로 model을 pre-train한다.
- pre-trained model을 가지고 pseudo-labeling을 통해 unlabeled dataset에 labeling을 수행한다.
- labeled dataset과 pseudo-labeled dataset 둘 다 model에 재학습시킨다.

Self-training
Augmentation + Teacher-Student networks + semi-supervised learning을 모두 합친 학습법이다.
- labeled dataset으로 model을 학습시킨다.
- 학습된 model로 pseudo-labeling을 통해 unlabeled dataset에 labeling을 수행한다.
- labeled dataset과 pseudo-labeled dataset 둘 다 model에 학습을 시키는데 RandAugment를 사용하여 더 방대한 data를 적용한다.
- 학습된 Student Model은 이전의 Teacher Model에 대체하고 다시 1번부터 진행하고 Student Model 또한 새로운 Student Model을 도입하여 학습을 진행한다. (Student Model이 조금씩 커진다.)

CutMix
regional dropout strategies는 generalizaiton과 localization performance를 향상 시켜주지만 정보에 대한 것도 줄어들기 때문에 data hungry 현상이 나타난다. 이 문제를 해결하기위해 고안해낸 기법이 CutMix이다.
CutMix는 어떤 영역을 다른 이미지에 대체시키는 방법으로 data hungry가 나타나지않고 효율적으로 학습된다. 또한 regional dropout의 이점을 유지하면서 non-discriminative(식별되지않는)부분에 주의한다. 이렇게 patch들을 추가하면서 object의 부분적인면을 식별하는데 요구되는 localization 기능이 더 향상되는 것이다.
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp 6주차] 피어세션과 학습 회고 (0) | 2021.09.09 |
|---|---|
| [Boostcamp Day-27] Computer Vision - Image Classification 2 (0) | 2021.09.08 |
| [Boostcamp Day-25] Computer Vision - Image Classification 1 (0) | 2021.09.06 |
| [Wrap-up report] Image Classification (0) | 2021.09.03 |
| [실험 일지 작성_목] Image Classification (0) | 2021.09.02 |