728x90
model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델 형태(architecture)와 파라미터를 저장
- 모델 학습 중간 과정의 저장을 통해 최선의 결과 모델을 선택
- 만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
# staet_dict : 모델의 parameter를 표시
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tendor].size())
# 모델의 parameter 저장
torch.save(model.state_dict(), os.path.join(MODEL_PATH, 'model.pt'))
# 같은 모델의 형태에서 parameter만 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt")))
# 모델의 architecture와 함께 저장
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
# 모델의 architecture와 함께 load
model = torch.load(os.path.join(MODEL_PATH, "model.pt"))checkpoints
- 학습의 중간 결과를 저장하여 최선의 결과를 선택
- earlystopping 기법 사용시 이전 학습의 결과물을 저장
- loss와 metric 값을 지속적으로 확인 저장
- 일반적으로 epoch, loss, metric을 함꼐 저장하여 확인
- cobal에서 지속적인 학습을 위해 필요
# 모델의 정보를 epoch와 함꼐 저장
torch.save({
'epoch' : e,
'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'loss' : epoch_loss,
},f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']Transfer learning
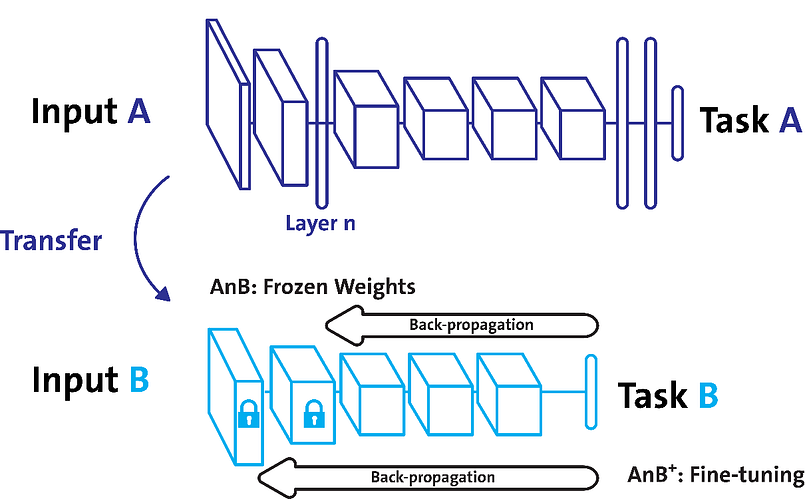
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 일반적으로 대용량 데이터셋으로 만들어진 모델의 성능이 높다.
- 현재의 DL에서는 가장 일반적인 학습 기법
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행
- Freezing : pretrained model 활용시 모델의 일부분을 frozen 시킴
vgg = models.vgg16(pretrained=True).to(device)
class MyNewNet(nn.Module):
def __init__(self):
super().__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# 마지막 레이어를 제외하고 frozen
for param in my_model.parameters():
param.requires_grad = False
for parma in my_model.linear_layers.parameters():
param.requires_grad = TrueTensorboard
- TensorFlow의 프로젝트로 만들어진 시각화 도구
- 학습 그래프, metric, 학습 결과의 시각화 지원
- PyTorch도 연결 가능 -> DL 시각화 핵심 도구
scalar : metric 등 상수 값의 연속(epoch)을 표시
graph : 모델의 computational graph 표시
histogram : weight 등 값의 분포를 표현
Image : 예측 값과 실제 값을 비교 표시
mesh : 3d 형태의 데이터를 표현하는 도구
import os
logs_base_dir = "logs"
os.makedirs(logs_base_dir, exist_ok=True) #Tensorboard 기록을 위한 directory 생성
from torch.utils.tensorboard import SummaryWriter #기록 생성 객체 SummaryWriter 생성
import numpy as np
writer = SummaryWriter(logs_base_dir)
for n_iter in range(100): #n_iter: x축의 값
#add_scalar : scalar 값을 기록
writer.add_scalar('Loss/train',np.random(), n_iter) #Loss/train : loss category에 train 값
writer.add_scalar('Loss/test',np.random(), n_iter)
writer.add_scalar('Accuracy/train',np.random(), n_iter)
writer.add_scalar('Accuracy/test',np.random(), n_iter)
writer.flush() #값 기록(disk에 쓰기)
%load_ext tensorboard
%tensorboard --logdir {logs_base_dir}weight & biases
- 머신러닝 실험을 원활히 지원하기 위한 상용도구
- 협업, code versioning, 실험 결과 기록 등 제공
- MLOps의 대표적인 툴로 저변 확대 중
!pip install wandb -q
# config 설정
config = {"epochs":EPOCHS, "batch_size":BATCH_SIZE, "learning_rate":LEARNING_RATE}
wandb.init(project="my-test-project", config=config)
# wnadb.config.batch_size = BATCH_SIZE
# wnadb.config.learning_rate = LEARNING_RATE
for e in range(1, EPOCHS + 1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in train_dataset:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
# ...
optimizer.step()
# ...
wandb.log({'accuracy':train_acc, 'loss':train_loss}) #기록 add_~ 함수와 동일728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp 3주차] 피어세션과 학습 회고 (0) | 2021.08.20 |
|---|---|
| [Boostcamp Day-14] PyTorch - Multi_GPU, Hyperparameter, Troubleshooting (0) | 2021.08.20 |
| [Boostcamp Day-12] PyTorch - AutoGrad & Optimizer, Dataset & Dataloader (0) | 2021.08.18 |
| [Boostcamp Day-11] PyTorch - PyTorch Basics (0) | 2021.08.18 |
| [Boostcamp Day-10] DL Basic - Generative Models (0) | 2021.08.13 |