Tensor
Tensor는 다차원 Arrays 를 표현하는 PyTorch 클래스이다. 사실상 사실상 numpy의 ndarray와 동일하며 Tensor를 생성하는 함수도 거의 동일하다.
# numpy
import numpy as np
n_array = np.arange(10).reshape(2, 5)
# pytorch
import torch
t_array = torch.FloatTensor(n_array)Array to Tensor
Tensor 생성은 list나 nparray를 사용 가능하고 기본적으로 tensor가 가질 수 있는 data 타입은 numpy와 동일하다.
# data to tensor
data = [[3,5], [10,5]]
x_data = torch.tensor(data)
# ndarray to tensor
nd_array_ex = np.array(data)
tensor_array = torch.from_numpy(nd_array_ex)numpy like operations
data = [[3, 5, 20],[10, 5, 50], [1, 5, 10]]
x_data = torch.tensor(data)
x_data[1:]
x_data[:2, 1:]
x_data.flatten()
torch.ones_like(x_data)
x_data.numpy()
x_data.shape
x_data.dtype
# 다음과 같이 pytorch의 tensor는 GPU에 올려서 사용가능하다.
x_data.device
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')
x_data_cuda.deviceTensor handling
- view : reshape과 동일하게 tensor의 shape을 변환한다.
- squeeze : 차원의 개수가 1인 차원을 삭제(압축)한다.
- unsqueeze : 차원의 개수가 1인 차원을 추가한다.
1. view와 reshape의 차이
tensor_ex = torch.rand(size=(2,3,2))
tensor_ex
tensor_ex.view([-1, 6])
tensor_ex.reshape([-1, 6])그런데 view도 tensor의 shape을 변환하고 reshape도 tensor의 shape을 변환하는데 무슨 차이가 있는 것일까?
우선 다음과 같은 코드를 실행해보자.
a = torch.zeros(3, 2)
b = a.view(2,3)
a.fill_(1)
print(b)
## tensor([[1., 1., 1.],
## [1., 1., 1.]])
print(a)
## tensor([[1., 1.],
## [1., 1.],
## [1., 1.]])
c = torch.zeros(3, 2)
d = c.t().reshape(6)
c.fill_(1)
print(d)
## tensor([0., 0., 0., 0., 0., 0.])
print(c)
## tensor([[1., 1.],
## [1., 1.],
## [1., 1.]])view를 사용했을때 tensor의 데이터가 a와 b 모두 같지만 reshape을 사용했더니 c와 d의 데이터가 다른 모습이다. 왜 이러는 건지 이유를 찾아보면 우선 contiguous()라는 것을 알아야한다.
- contiguous()
예를 들어 다음과 같은 2D Tensor가 있다고 하자.
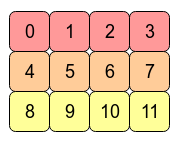
그러면 메모리에는 다음과 같이 연속적으로 할당된다.

여기서 각 column으로 이동할 때는 1씩 이동하면 되지만 각 row로 이동하려면 4씩 이동해야한다. 그렇다면 transpose 연산을 했을 때 어떻게 될 것인가이다.

transpose를 하게되면 각 원소의 위치는 변화가 되지않고 index만 변화된다. 즉, 위 그림을 보면 0에서 4이동하려면 4만큼 건너뛰어야한다는 것이다. 이러한 것을 연속성이 보장되지않는다고 한다.
여기까지 대충 contiguous에 대해서 설명을 해보았다. 이제 reshape을 했을 때 왜 data가 달라지냐는 것이다. 그 이전에 다음과 같은 코드를 실행해보자.
a = torch.zeros(3, 2)
b = a.t().view(6,)
a.fill_(1)결과는 에러가 난다. 그런데 위에서는 reshape을 했을 때 정상적으로 실행이되었었다. 이 말은 a를 transpose를 했을 때 contiguous하지 않으므로 view가 실행이 되지 않는다라고 할 수 있다.
reshape이 contiguous하지 않는 tensor 임에도 불구하고 실행되는 이유는 copy가 되기 때문이다. 다시말해 contiguous한 tensor는 데이터를 서로 공유하고 contiguous하지 않은 tensor는 copy가 되어 서로 데이터가 공유되지 않는다는 것이다. 이것은 다음과 같은 코드로 확인할 수 있다.
a = torch.zeros(3, 2)
b_ = a.t()
b = a.t().contiguous() #연속적으로 만들어줌 -> copy가 됨
b = b.view(6,)
a.fill_(1)
print(b_)
## tensor([[1., 1., 1.],
## [1., 1., 1.]])
print(b)
## tensor([0., 0., 0., 0., 0., 0.])
print(a)
## tensor([[1., 1.],
## [1., 1.],
## [1., 1.]])
c = torch.zeros(3, 2)
d = c.reshape(2, 3)
c.fill_(1)
print(d)
## tensor([[1., 1., 1.],
## [1., 1., 1.]])
print(c)
## tensor([[1., 1.],
## [1., 1.],
## [1., 1.]])2. Squeeze와 Unsqueeze
Squeeze와 Unsqueeze는 다음 그림을 보면 이해하기 쉽다.
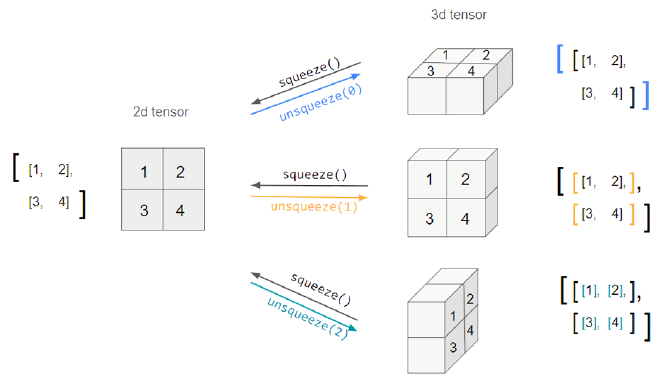
위 2d tensor의 shape을 (2, 2)라고 표현한다면 앞의 2는 0 위치에 있고 뒤의 2는 1 위치에 있다고 할 수 있다. 만약 unsqueeze(0)이라고 한다면 0 위치에 차원이 하나가 더 생겨 (1, 2, 2)가 될 것이고 unsqueeze(1)이라고 한다면 1위치에 차원이 하나가 더 생겨 (2, 1, 2)가 되는 것이다. squeeze는 반대로 이런 1인 차원을 삭제하는 함수이다.
Tensor operations
행렬곱셈 연산 함수는 dot이 아닌 mm을 사용한다.
n2 = np.arange(10).reshape(5, 2)
t2 = torch.FloatTensor(n2)
t1.mm(t2) # 두 행렬이 모두 2d square matrix일 때 사용
t1.matmul(t2) # 일반적인 행렬 곱으로 broadcasting이 지원된다.
# bmm()은 두 행렬이 모두 3d square matrix일 때 사용한다.nn.functional
다음과 같이 다양한 수식 변환을 지원한다.
import torch.nn.functional as F
tensor = torch.FloatTensor([0.5, 0.7, 0.1])
h_tensor = F.softmax(tensor, dim=0)
y = torch.randint(5, (10, 5))
y_label = y.argmax(dim=1)
torch.nn.functional.one_hot(y_label)★AutoGrad
PyTorch의 핵심은 자동 미분을 지원한다는 것이다.
w = torch.tensor(2.0, requires_grad=True)
y = w ** 2
z = 10 * y + 2
z.backward() # 미분
w.grad() #미분 값다음과 같이 변수가 a, b 두개 일때는 gradient를 지정해주어야한다.
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
print(a.grad())
print(b.grad())자세한 설명과 내용은 다음 블로그를 참고하면 도움이 많이된다.
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp Day-13] PyTorch - Transfer learning, Tensorboard & wandb (0) | 2021.08.19 |
|---|---|
| [Boostcamp Day-12] PyTorch - AutoGrad & Optimizer, Dataset & Dataloader (0) | 2021.08.18 |
| [Boostcamp Day-10] DL Basic - Generative Models (0) | 2021.08.13 |
| [Boostcamp Day-9] DL Basic - Transformer (0) | 2021.08.13 |
| [Boostcamp Day-9] DL Basic - Recurrent Neural Network (0) | 2021.08.12 |