신경망(neural network)
신경망을 이해하기 전에 우선 선형모델에 대해서 알아야한다.

선형 모델은 가중치를 나타내는 W를 X에 곱한 후 y절편이라고 할 수 있는 b(bias)를 더한 식이다. 수식으로 표현하면 X⋅W + b이고 이 식을 바로 'Neuron'이라고 할 수 있다.
활성함수(activation function)
신경망은 위에서 말한 선형모델과 활성함수를 합성한 함수이다.

위 그림에서 σ(z)이 바로 활성함수이고 활성함수는 sigmoid, tanh, ReLU 등이 있다. 우선 sigmoid에 대해서 알아보면 다음과 같은 그래프와 수식으로 되어있다.

sigmoid는 0~1을 출력하는 함수인데 이 함수를 조금 더 개선해서 다음과 같은 tanh함수가 생겼다.

tanh는 -1~1을 출력하여 sigmoid보다 큰 범위를 가지기때문에 더 빠르게 수렴하는 특징이 있다. 하지만 sigmoid와 tanh는 vanishing gradient problem을 가지고 있다. 그리고 이 문제를 해결하기 위해 생긴 것이 ReLU 함수이다.
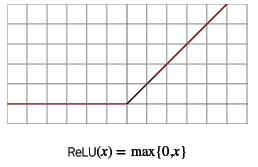
다층 퍼셉트론(Multi Layer Perceptron, MLP)
다층 퍼셉트론은 위에서 설명한 신경망이 여러층 합성된 함수이다. 도식으로 표현하면 다음과 같다.

맨 아래 x부터 순차적으로 신경망을 계산해나가면 이 과정을 순전파(forward propagation)이라고 한다.
이 신경망의 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 줄어들어 좀 더 효율적으로 학습이 가능하다. 단, 간단한 문제일 때 쓸데없이 층이 깊어지면 overfitting이 일어날 수 있다.
역전파(backpropagation)
앞서 설명한 순전파의 과정을 거친 후 가중치를 업데이트하기 위해 거꾸로 윗층부터 아래층 방향으로 계산하게 되는데 이런 과정을 역전파(backpropagation)이라고 한다. 또한 이 역전파 과정을 진행하기 위해서 연쇄법칙(chain rule)을 사용한 미분이 이루어진다.

소프트맥스(softmax)
소프트맥스는 우선 각 class별로 확률 값을 출력해주는 함수이다. 예를 들어서 class가 [0, 1, 2]가 있고 소프트맥스 함수로 연산했을시 각 class에 속할 확률 [0.24, 0.67, 0.09]와 같은 값을 출력해준다는 것이다. 그리고 출력된 확률 값들 [0.24, 0.67, 0.09]의 합은 항상 1이다. 수식으로 표현하면 다음과 같다.

좀 더 이해하기 쉽게 다시 설명한다면 만약 클래스가 총 3개가 있고 각 클래스에 속할 확률을 소프트맥스를 통해 출력한다고 해보자. 그러면 아래와 같이 식을 작성할 수가 있고 쉽게 말해 'k번째 클래스일 확률/전체 확률'이라고 할 수 있다.

주로 분류 문제를 해결할 때 사용한다.
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp Day-2] Python - Function and Console IO (0) | 2021.08.03 |
|---|---|
| [Boostcamp Day-2] AI Math - 확률론 (0) | 2021.08.03 |
| [Boostcamp Day-1] Python - variables(변수) (0) | 2021.08.02 |
| [Boostcamp Day -1] Python - 코딩 환경 (0) | 2021.08.02 |
| [Boostcamp Day-1] AI Math - 경사하강법 (0) | 2021.08.02 |