개인적으로 과대적합과 과소적합의 이해가 많이 헷갈렸다. 따라서 여러번 예시를 작성하여 설명하겠다.
과소적합(underfitting): 데이터에서 충분히 특징을 찾아내지 못하고 머신러닝 모델을 학습할 경우
과대적합(overfitting): 필요 이상의 특징으로 학습할 경우
위와 같이 간단하게 적어놓으면 전혀 감을 잡지 못한다.
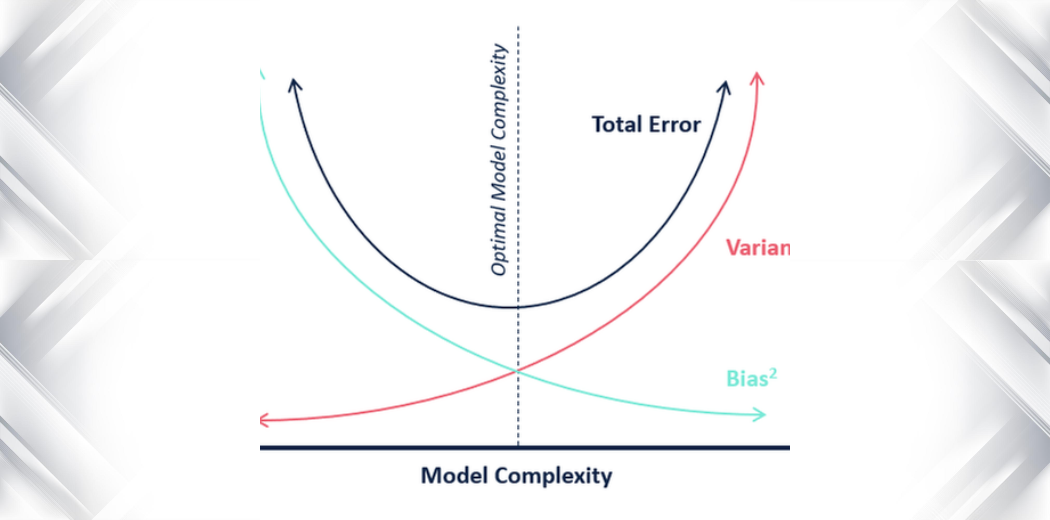
출처: [https://www.analyticsvidhya.com/blog/2020/08/bias-and-variance-tradeoff-machine-learning/]
위와 같이 수학적으로 데이터에서 필요 이상으로 추출할 경우 분산(variance)이 높아지고, 반대로 필요 이하로 추출할 경우 편향(bias)이 높아진다. 예를 들어 감자를 썰 때 필요 이상으로 썰면 너무 작게 많이 썰어져서 제대로 특징을 알지 못하고 너무 필요 이하로 크게 썰어버리면 특징이 너무 적다는 말이다.
아직까지는 제대로 이해하지 못하겠다.
과소적합
과소적합은 충분한 데이터의 특징을 활용하지 못할 경우이고 편향이 높아질 때를 말한다.
| 사물 | 분류값 | 생김새 |
|---|---|---|
| 야구공 | 공 | 동그라미 |
| 농구공 | 공 | 동그라미 |
| 테니스공 | 공 | 동그라미 |
| 딸기 | 과일 | 세모 |
| 포도알 | 과일 | 동그라미 |
위와 같은 표가 있을 때 해당 사물을 공인지 과일인지를 판단하기 위해서는 생김새를 보고 판단한 것이라고 생각할 것이다. 하지만 생김새만으로는 정확하게 분류할 수가 없다. 만약 생김새가 동그라미라면 포도알도 있고 야구공도 있는데 이것은 공인지 과일인지를 판단하지 못한 것이다.
즉, 공과 과일을 구별할 수 있는 특징이 너무 적기 때문에 분류가 정확하지 않게 되는 것이다. 이처럼 충분하지 못하고 너무 적은 특징만으로 학습되어 특정 특징에만 편항되게 학습된 모델을 "과소적합"된 모델이라 부른다.
이제 "과소적합"이라는 것에 대해서 이해할 수 있을 것이다.
과대적합
과대적합은 데이터에서 필요 이상으로 특징을 발견해서 학습 데이터에 대한 정확도는 상당히 높지만 테스트 데이터 또는 학습 데이터 외의 데이터에는 정확도가 낮게 나오는 것을 말한다. 또한 분산이 높아질 때를 말한다.
| 사물 | 분류값 | 생김새 | 크기 | 줄무늬 |
|---|---|---|---|---|
| 테니스공 | 공 | 원형 | 중간 | 있음 |
| 딸기 | 과일 | 세모 | 중간 | 없음 |
| 포도알 | 과일 | 원형 | 작음 | 없음 |
위와 같은 특징을 사용한다면 해당 사물들에 대해서 정확한 분류를 할 수 있는 머신러닝 모델을 만들 수 있다. 하지만 아래와 같은 사물들에대해서는 정확하지 않은 분류값을 내놓는다.
테니스 공을 예로 들어서 보면 테니스공은 원형이고 중간 크기에 줄무늬가 있다. 하지만 아래에 있는 표를 보면 원형이고 중간 크기에 줄무늬가 있는 사물이 없다. 따라서 테니스공의 특징이 과하게 학습되어 다른 사물들도 정확하게 분류할 수가 없다.
| 사물 | 분류값 | 생김새 | 크기 | 줄무늬 |
|---|---|---|---|---|
| 골프공 | 공 | 원형 | 작음 | 없음 |
| 수박 | 과일 | 원형 | 큼 | 있음 |
| 당구공 | 공 | 원형 | 중간 | 없음 |
| 럭비공 | 공 | 타원형 | 큼 | 있음 |
| 볼링공 | 공 | 원형 | 큼 | 없음 |
이처럼 학습 데이터는 높은 정확도를 가지지만 실제 데이터에서는 낮은 정확도를 보일 경우 과대적합을 의심한다.
과대적합을 피하기위한 방법으로는 더 많은 데이터를 확보해서 부족한 학습 데이터를 채우는 방법이 있고 사용된 특징을 줄여보는 방법도 있다. 또한 특징들을 수치값으로 바꿔서 특정 특징의 비중(편향)을 줄이는 방법도 있다.
'Machine Learning > Theory' 카테고리의 다른 글
| 의사결정 트리(decision tree) (0) | 2021.05.30 |
|---|---|
| SVM(Support Vector Machine) (0) | 2021.05.25 |
| k-최근접 이웃(k-Nearest Neighbor, kNN) (0) | 2021.05.21 |
| 혼동 행렬과 교차 검증 (0) | 2021.05.19 |
| 지도학습과 비지도학습 (0) | 2021.05.19 |