Introduction
- 어떤 것을 설계할때 숫자 매개변수를 통해서 수정하게 되면 일관성있게 진행할 수 있다.
- 수정하면서 관련된 모든 것들을 수정하게되는데 이때 반복적인(중복된) 노력이 든다. 결국 이런 반복적인 일을 줄이고자하는 것이 목적인 것 같다.

- 엔지니어들은 가끔씩 위처럼 손으로 대충 그린 것을 자동으로 변환해주는 것을 원한다. (실제로 손으로 그리는 것은 많이 못 봤다... 진짜로 원하는 사람이 많은지는 모르겠다.)

- 해당 논문에서 소개하는 generate model인 Vitruvion은 autoregressive하게 constraint와 primitive를 sampling하여 일관성있는 CAD sketch를 만들어낸다.
- constraint graph를 통해 sketch를 생성할 수 있는 것은 자동으로 수정할 수 있는 기능을 가능하게 만든다.
- Vitruvion은 세 가지에서 증명했다.
- autocomplete: 그리다만 sketch를 주면 이어서 그럴듯하게 완성시켜주는 것
- autoconstrain: constraint를 예측하여 넣어주는 것
- image-conditional synthesis: 이미지에서 primitive와 contraint를 예측하여 sketch를 만드는 것
Method
sketch generation task는 primitive generation, constraint generation, constarint solving으로 나누어진다. primitive generation과 constraint generaton은 학습된 모델로 수행하고 constraint solving은 D-Cubed와 같은 것을 사용한다고 한다. 그리고 primitive model과 constraint model로 나누어 구현하기 쉽게 했다고 한다.
전체 과정을 수식으로 나타내면 다음과 같다.

- P: sequence of primitive
- C: sequence of constraint
- S: sketch
- ctx: image나 prefix(primer)와 같은 context
Primitive Model
primitive model은 primitive sequence의 autogressive generation을 수행한다. 각 sketch에 대해서 다음과 같이 분포를 구한다고 한다.

- $N_P$: sequence에서 primitive의 개수
- 각 primitive는 (type, parameters)의 tuple 형식으로 되어있다.
# https://github.com/JadeKim042386/vitruvion/blob/main/img2cad/dataset.py
class PrimitiveDataset(torch.utils.data.Dataset[SketchTokenSet]):
"""This dataset encapsulates a sequence of sketch as a dataset of tokenized primitives."""
def __init__(self, sequence_file: str, num_bins: int, max_length: Optional[int]=None, permute: bool=False):
"""Create a new primitive dataset from the given sequence.
Parameters
----------
sequence_file : str
Path to the sequence file containing the sketch data.
num_bins : int
Number of bins to used for quantizing positional features.
max_length : int, optional
If not `None`, the length to which the sequences are padded or truncated.
Otherwise, no padding / truncation is performed.
permute : bool, optional
If True, the primitives are randomly permuted.
Note, this breaks constraint references. (default False)
"""
super().__init__()
self.sequences = flat_array.load_dictionary_flat(sequence_file)['sequences']
self.max_length = max_length
self.num_bins = num_bins
self.permute = permute
def __getitem__(self, idx: int) -> Dict[str, torch.Tensor]:
seq = self.sequences[idx]
sketch = datalib.sketch_from_sequence(seq)
i2c_utils.normalize_sketch(sketch)
sample, _ = tokenize_sketch(sketch, self.num_bins, self.max_length,
permute=self.permute)
sample = {k: torch.from_numpy(v) for k, v in sample.items()}
return sample
def __len__(self) -> int:
return len(self.sequences)Ordering
위 코드에서 datalib.sketch_from_sequence를 통해서 design 순서를 보존할 수 있다. 따라서 이 순서에따라 autocomplete를 수행할 수 있게 학습할 수 있다.
Normalization
def normalize_sketch(sketch):
center_sketch(sketch)
scale_factor = rescale_sketch(sketch)
return scale_factor모호성을 줄이기 위해 (0, 0)을 중심으로 1 meter의 bounding box안에 sketch를 옮기고 bounding box 안에 모든 sketch가 들어가도록 rescale한다.
Parameterization
# https://github.com/JadeKim042386/vitruvion/blob/1b91fff5597b3a4e272e6490e4d458f3ef790e62/img2cad/dataset.py#L143C8-L143C8
params = i2c_utils.parameterize_entity(ent)
# https://github.com/JadeKim042386/vitruvion/blob/main/img2cad/data_utils.py#L274
def parameterize_entity(ent) -> np.array:
param_by_type = {
Arc: _parameterize_arc,
Circle: _parameterize_circle,
Line: _parameterize_line,
Point: _parameterize_point
}
param_fn = param_by_type.get(type(ent))
if param_fn is None:
return None
return param_fn(ent)각 primitive의 entity의 parameter를 다음 table과 같이 최소화한다. 이는 parameter가 필요 이상으로 많은 over-parameterization 을 보완한다.

Quantization
def quantize_params(params: np.ndarray, n_bins):
min_val, max_val = MIN_VAL, MAX_VAL
params = np.around(params, decimals=10)
if (params < min_val).any() or (params > max_val).any():
raise ValueError("Parameters must be in [%f, %f]. Got [%f, %f]."
% (min_val, max_val, np.min(params), np.max(params)))
params_quantized = (params - min_val) / (max_val - min_val) * n_bins
params_quantized = params_quantized.astype('int32')
# Handle max_val edge case
params_quantized[params_quantized == n_bins] -= 1
return params_quantized6-bit uniform quantization을 적용한다.
Tokenization
# https://github.com/JadeKim042386/vitruvion/blob/main/img2cad/dataset.py#L155-L157
val_tokens.extend(param_bins + len(Token))
coord_tokens.extend(COORD_TOKEN_MAP[type(ent)])
pos_tokens.extend([pos_idx] * param_bins.size)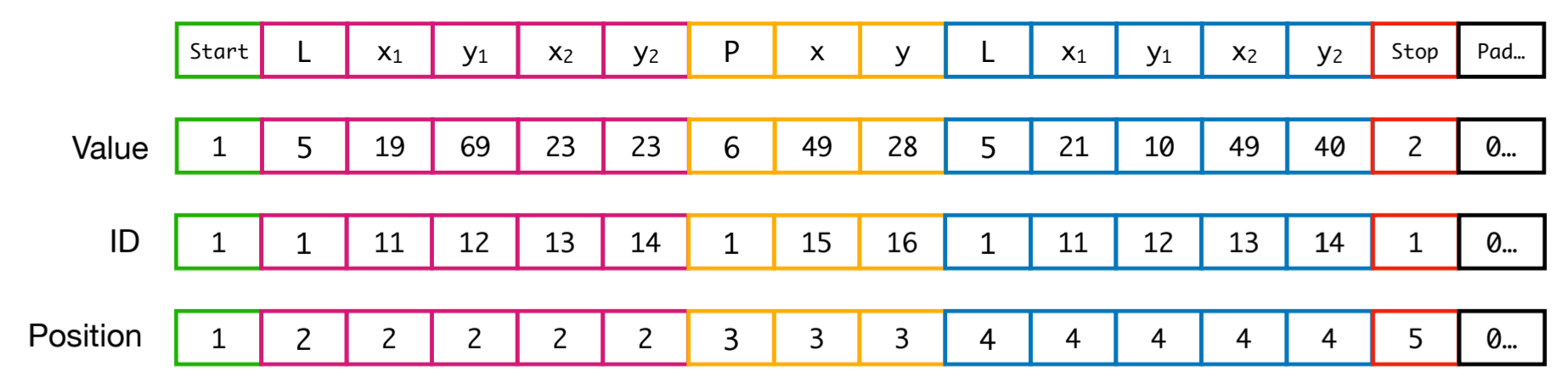
(value, ID, position token)으로 표현한다.
- value: primitive type과 parameter 값
- ID: paramter type
- position: primitive index
# https://github.com/JadeKim042386/vitruvion/blob/main/img2cad/dataset.py#L85
embeddings = self._embed_tokens(src)
if init_embedding is not None:
embeddings[:,0,:] += init_embedding
# Pass to transformer
output = self._feed_transformer(embeddings)
return outputEmbedding
# https://github.com/JadeKim042386/vitruvion/blob/1b91fff5597b3a4e272e6490e4d458f3ef790e62/img2cad/modules.py#L72
embed_layers, out = create_prim_embed_layers(num_bins, max_entities, embed_dim)
self.val_embed, self.coord_embed, self.pos_embed = embed_layersvalue, coordinate, position으로 embedding layer를 나누며 고정된 길이로 embedding한다.
Architecture
# https://github.com/JadeKim042386/vitruvion/blob/1b91fff5597b3a4e272e6490e4d458f3ef790e62/img2cad/modules.py#L78C9-L81C56
self.transformer = TransformerModel(embed_dim,
num_heads,
fc_size,
num_layers)
# https://github.com/JadeKim042386/vitruvion/blob/1b91fff5597b3a4e272e6490e4d458f3ef790e62/img2cad/modules.py#L34C9-L37C24
encoder_layers = TransformerEncoderLayer(embed_dim, num_heads, fc_size,
dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers,
num_layers)
# Linear output layer for softmax
self.linear_decode = linear_decode
if linear_decode:
self.out = out논문에서는 decoder-only transformer 기반의 architecture라고 설명했고 실제 코드로는 TransformerEncoder와 linear layer + softmax로 이루어져있다.
'Deep Learning' 카테고리의 다른 글
| Dive into Mojo🔥 (0) | 2023.07.23 |
|---|---|
| [Paper] VITRUVION: A GENERATIVE MODEL OF PARAMETRIC CAD SKETCHES (2) (0) | 2023.07.03 |
| 외부 CAD Data로 SketchGraphs 데이터셋 생성 with python (3) (0) | 2023.06.16 |
| 외부 CAD Data로 SketchGraphs 데이터셋 생성 with python (2) (0) | 2023.06.11 |
| 외부 CAD Data로 SketchGraphs 데이터셋 생성 with python (1) (0) | 2023.06.04 |