728x90
WSSS

Pixel-level labeling이 image-level labeling보다 약 78배 오래걸림 -> 만드는 시간이 짧은 image-level label만 가지고 segmentation 하는 방법을 모색
1. Weak Supervision
테스트 시에 요구하는 output보다 학습 시에 더 간단한 annotation을 이용하여 학습
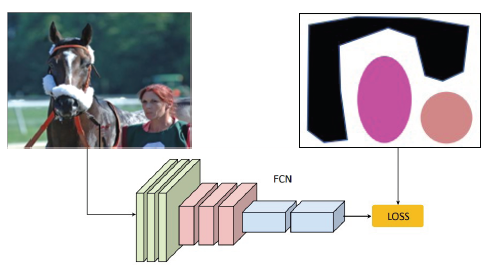
- 가지고 있는 정보인 image level label을 활용하기 위한 classification 모델 학습
- 학습한 classification 모델을 통해서 CAM, Grad-CAM, 혹은 attention 추출
- 추출한 결과물은 pseudo mask로 segmentation 모델 학습에 이용
- pseudo-mask의 결과가 좋지 않음
CAM & Grad-CAM
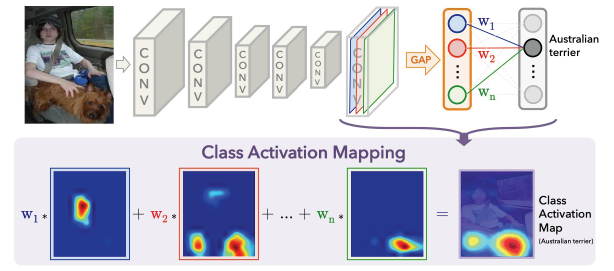
- Classification 모델을 학습하면서 생성이 가능
- 특정 class의 물체가 사진의 어떤 영역에 있는지 유추 가능
1. Image Feature
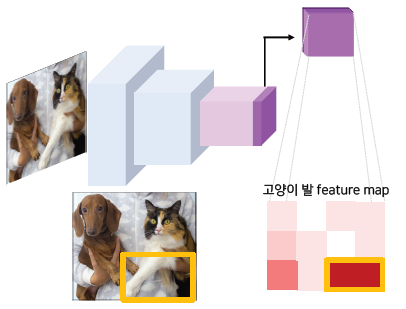
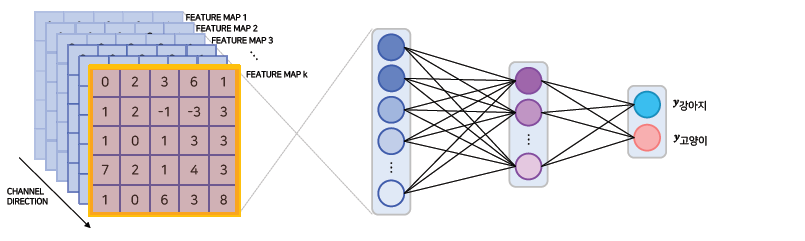
- 모델은 학습 시에 고양이인지 강아지인지 구분 할 feature map을 생성
- 각 feature map은 고양이인지 강아지인지를 구분하기 위한 정보를 담고 있음
- 각 feature map은 다른 정보를 담고 있음
- Feature map은 flatten/pooling되어 이미지가 어떤 class인지 판별하는데 쓰임
- GAP(Global Average Pooling)의 결과물은 각 feature map의 공간적인 평균값으로 해당 feature map을 대표하는 값
- Classifier는 GAP(또는 Flatten)된 feature vector의 각 원소에 class 별로 다른 weight를 주어서 점수를 매김
2. CAM
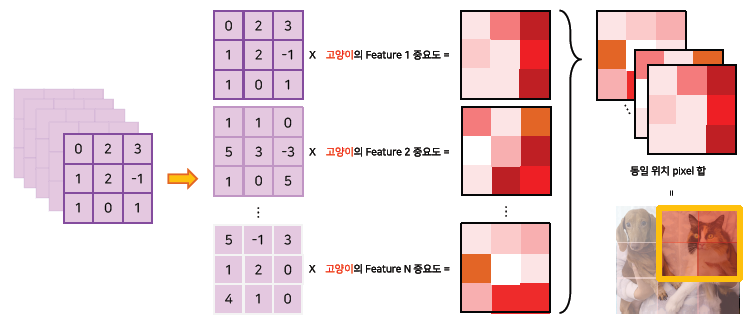
- Classification을 통해서 학습한 중요도를 GAP 이전의 feature map에 곱함
- 어떤 영역이 class인지 판단함에 있어서 중요했는지 알 수 있음
- Score가 높은 영역이 중요한 영역
- 마지막 레이어는 꼭 GAP을 가져야하기 때문에 일반적인 적용이 불가능
- 마지막 레이어에서만 CAM을 만들 수 있기때문에 이전 레이어에서는 어떻게 활성화 되고 있는지 확인 할 수 없음
3. Grad-CAM
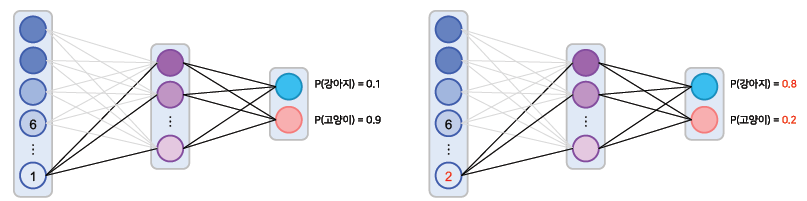
- 특정 featue map에 변화가 있을 때, class score에도 변화가 크게 일어난다면 중요도가 높은 feature라고 생각할 수 있음
- 변화량/변화량 = 기울기 = 미분값으로 중요도가 정해짐
- k번째 feature map의 강아지 class에 대한 중요도 = $\frac{1}{n}\sum_{x,y}\frac{\partial y 강아지}{\partial f_k (x,y)}$ (N = 픽셀 수)

- Object의 모습을 반영하기 보다는 동글동글한 모양으로 Sharp하지 않게 생성됨
- 입력 이미지보다 작은 feature map을 통해서 CAM을 생성하기 때문
- Sharp한 모양으로 만들기 위한 접근
- 물체의 형태를 알 수 있는 정보를 제공
- Transfer Learning을 이용
- Self-supervised Learning을 이용
- 특징적인에만 집중하는 경향이 있음 (타조의 경우 몸통보다는 머리에 집중)
- 물체를 구별하기 위해 학습하기 때문에 CAM이 물체와 같은 모양을 할 이유가 적음
- 다른 class임을 확실하게 알 수 있는 특징에 의존
- 같은 class의 물체끼리 서로 다른 모습을 갖고 있기 때문에 공통적으로 보이는 특징에 의존
- CAM 영역을 확장하기 위한 접근
- 특징적인 영역을 지운 사진을 다시 학습하여 CAM을 얻음
- Output별로 다른 모델을 학습해야함
- Class 별로 필요한 Step이 다름
- 과도한 step으로 인해 물체가 아닌 영역까지 mask가 생기는 현상이 발생
- input 이미지의 random 영역을 지움
- Input 이미지에서 random한 patch를 지워서 최대한 다양한 영역에서 특징을 뽑을 수 없도록 강제
- 한 개의 네트워크로 Erasing과 비슷한 효과가 생김
- 다양한 Receptive Field 사용
- Mixup
- 특징적인 영역을 지운 사진을 다시 학습하여 CAM을 얻음
728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [주말 실험 일지 - 토] Pstages - Semantic Segmentation (0) | 2021.11.06 |
|---|---|
| [Boostcamp 13주차] 피어세션과 학습 회고 & 실험일지 (0) | 2021.10.29 |
| [Boostcamp Day-55] HRNet (High Resolution Network) (0) | 2021.10.29 |
| [주말 실험 일지 - 일] Pstages - Semantic Segmentation (0) | 2021.10.29 |
| [주말 실험 일지 - 토] Pstages - Semantic Segmentation (0) | 2021.10.29 |