728x90
EDA
1. Import
필요한 라이브러리를 import
import os
import math
import pandas as pd
import numpy as np
from scipy import stats
from PIL import Image
import matplotlib.pyplot as plt2. Data 확인
head() 또는 sample()을 사용하여 data를 확인해본다.
train = pd.read_csv("./train.csv")
train.head(10)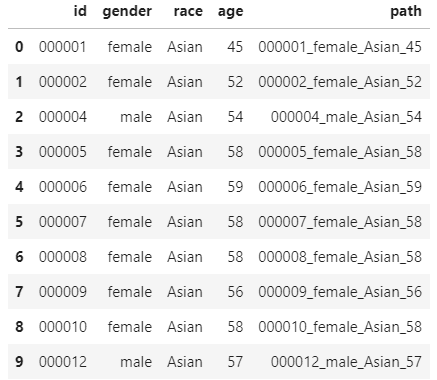
3. 필요없는 feature 삭제
id는 데이터 분석에 관련 없는 feature이고 race는 모두 "asian"이기 때문에 drop한다.
train.drop(["id", "race"], axis=1, inplace=True) # [id, race] drop4. 파일 개수 확인
- 마스크 착용 5장, 이상하게 착용 1장, 미착용 1장으로 총 7장의 이미지가 들어있는지 확인한다.
- 숨은 파일까지 나타날 수 있으므로 file.startswith('.')를 사용하여 filtering 한다.
# Check number of file
train['file_n'] = [len([file for file in os.listdir(f"./images/{directory}") if not file.startswith('.')]) for directory in train['path']]
train.describe()5. 전체 파일 개수 확인
sum(train['file_n'])
# after check number of file, drop
train.drop("file_n", axis=1, inplace=True)6. .jpg 파일로 통일
.png, .jpeg 등 파일 포맷이 다르게 분포되어있기 때문에 모두 .jpg로 바꿔 저장해주는 함수를 정의한다.
def to_jpg(directory_path, file_list):
file_list_png = [file for file in file_list if not file.endswith(".jpg")]
if file_list_png:
for f in file_list_png:
name = f.split('.')[0]
img = Image.open(f'{directory_path}/{f}')
img.save(f'{directory_path}/{name}.jpg')7. gender와 age에 따른 class 분류
- gender와 age를 입력받아 0~5의 값을 return한다.
- wear, incorrect, normal의 class 값은 각각 6씩 차이가 나이때문에 0~5의 값만 return해주어도 충분하다.
def class_classifier(gender, age):
label = 0
#Gender = Male
if gender == "male":
if age < 30:
label = 0
elif 30 <= age < 60:
label = 1
else:
label = 2
#Gender = Female
else:
if age < 30:
label = 3
elif 30 <= age < 60:
label = 4
else:
label = 5
return label8. image_path, label, age, gender를 return
- 위에서 정의한 to_jpg()와 class_classifier()를 사용하여 path와 label을 return 받는다.
- return 받은 path와 label와 그 크기에 맞게 age와 gender를 같이 return 한다.
def data_cleaning(directory):
_, gender, _, age = directory.split('_')
directory_path = f"./images/{directory}"
file_list = [file for file in os.listdir(directory_path) if not file.startswith('.')]
#png to jpg convert
to_jpg(directory_path, file_list)
file_list_jpg = [ "mask1.jpg", "mask2.jpg", "mask3.jpg", "mask4.jpg", "mask5.jpg", "incorrect_mask.jpg", "normal.jpg"]
# Save file full path with label
full_paths = [f"{directory_path}/{file}" for file in file_list_jpg]
label = class_classifier(gender, int(age))
labels = [label] * 5 + [label + 6, label + 12]
return full_paths, labels, [int(age)] * 7, [gender] * 79. DataFrame(image_path, label, age, gender) 생성
- dictionary에 모두 받은 후 dataframe으로 변환한다.
- describe()를 실행했을 때 데이터에서 60대는 60세 밖에 없다는 것을 확인
data = {'image_path' : [], 'label' : [], 'age' : [], 'gender' : []}
for directory in train['path']:
images, labels, age, gender = data_cleaning(directory)
data['image_path'] += images data['label'] += labels
data['age'] += age
data['gender'] += gender
data = pd.DataFrame(data)
data.head(10)
data.describe() # 60대는 60세 밖에 없음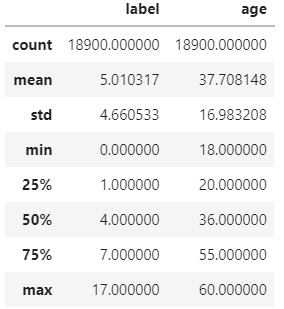
10. 연령별 분포 확인
- 10, 20, 30, 40, 50, 60대 각각의 데이터 수를 모두 합산
- 합산한 값을 다시 확률값으로 계산
- bar plot으로 10대와 60대 데이터가 부족하다는 사실을 확인
from collections import defaultdict
age_counts = defaultdict(int)
for age in data['age'].unique():
if age < 20:
age_counts['10'] += sum(data['age'] < 20)
elif age < 30:
age_counts['20'] += sum(data['age'] < 30)
elif age < 40:
age_counts['30'] += sum(data['age'] < 40)
elif age < 50:
age_counts['40'] += sum(data['age'] < 50)
elif age < 60:
age_counts['50'] += sum(data['age'] < 60)
else:
age_counts['60'] += sum(data['age'] < 70)
age_counts = dict(sorted(age_counts.items()))
# 10대와 60대의 데이터가 많이 부족함
total_counts = sum(age_counts.values())
for k in age_counts.keys():
age_counts[k] = (age_counts[k] / total_counts) * 100 # 확률 계산
fig, axes = plt.subplots(1, 1, figsize=(8, 8))
x = age_counts.keys()
y = age_counts.values()
axes.bar(x, y, width=0.7, edgecolor='black', linewidth=2, color='royalblue')
axes.spines['top'].set_visible(False)
axes.spines['right'].set_visible(False)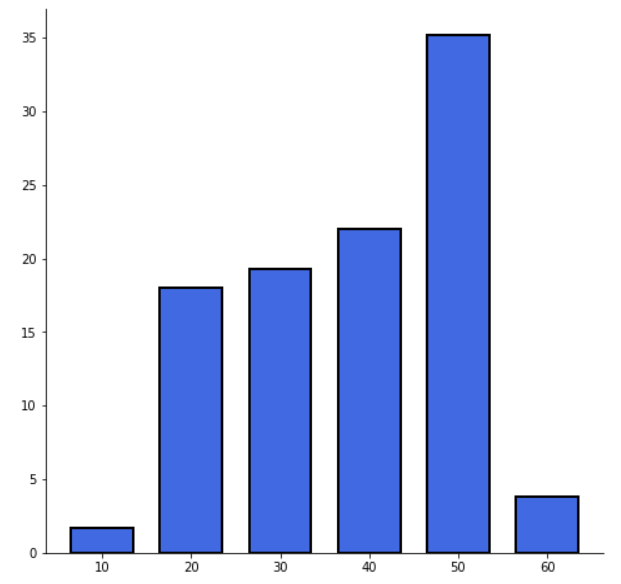
11. Gender별 데이터 분포 확인
- groupby를 통해 gender별 label 값을 grouping한다.
- male, female 각각 bar plot을 사용하여 비교
- female 데이터에 좀 더 편향되어있는 것을 확인
# Female 데이터에 편향됨
group = data.groupby('gender')['label'].value_counts().sort_index()
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
axes[0].bar(group['male'].index, group['male'], color='royalblue')
axes[0].set_xlabel('Male')
axes[1].bar(group['female'].index, group['female'], color='tomato')
axes[1].set_xlabel('Female')
for ax in axes:
ax.set_ylim(0, 4100)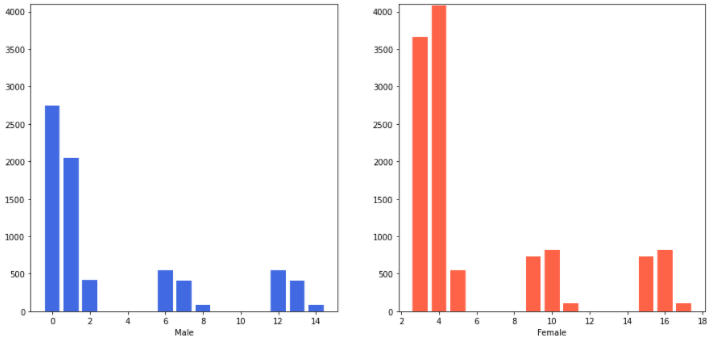
12. 이미지 사이즈 확인
첫 번째 데이터를 사용하여 이미지 사이즈를 확인
# Image Size Check
im = Image.open(data['image_path'][0])
im_array = np.array(im)
im_array.shape13. 분석 대상이 되는 객체 위치 확인
- 10개의 데이터를 확인하여 대부분 마스크가 가운데에 위치해있는 것을 확인
- 하지만 항상 마스크가 이미지 한가운데에 있다는 보장이 없기때문에 augmentation이 필요
# 분석 대상이 되는 객체 위치
transform = transforms.Compose([
Resize((600, 600), Image.BILINEAR),
CenterCrop((224, 224)),
])
fig, axes = plt.subplots(5, 5, figsize=(25,25))
idx = 0
for i in range(5):
for j in range(5):
axes[i][j].imshow(transform(Image.open(data['image_path'][idx])))
idx += 114. RGB 채널별 통계량 분석
- 첫 번째 데이터를 사용하여 채널별 array를 생성
- count, mean, std, max는 모두 비슷하지만 min 값에서 차이가 나타남
# RGB별 통계값
im = np.array(Image.open(data['image_path'][0]))
im_df_red = pd.DataFrame(im[0])
im_df_green = pd.DataFrame(im[1])
im_df_blue = pd.DataFrame(im[2])
print(im_df_red.describe())
print()
print(im_df_green.describe())
print()
print(im_df_blue.describe())
print()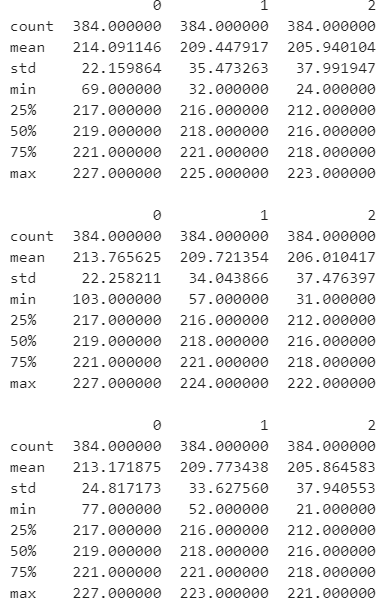
15. label의 독립적 분포
0, 1, 3, 4에 집중적으로 분포되어있는 것이 확인됨
# y의 독립적 분포 - 고르게 분포되어있지 못함
fig = plt.figure(figsize=(9,9))
ax = fig.add_subplot(111)
ax.hist(data['label'], bins=18, label='bins=18')
ax.set_xlim(-1, 18)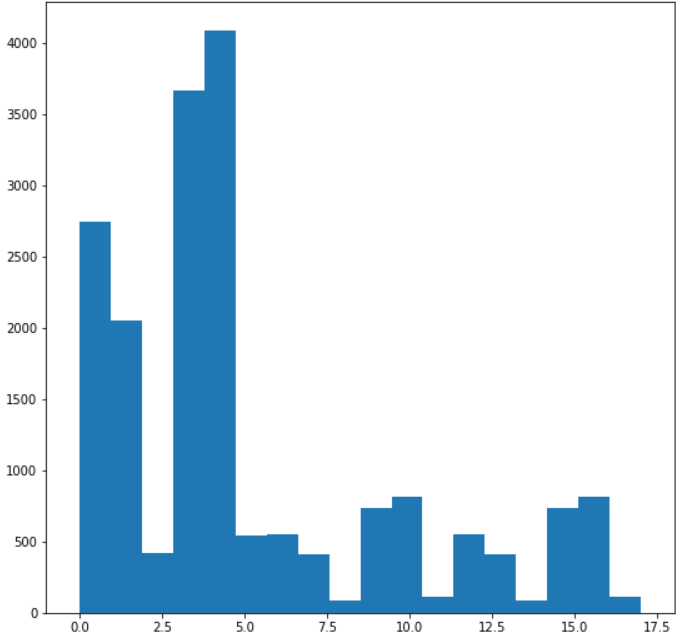
728x90
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp 4주차] 피어세션과 학습 회고 (0) | 2021.08.24 |
|---|---|
| [Boostcamp Day-15] Image Classification - Problem Definition (0) | 2021.08.24 |
| [Boostcamp Day-15] Image Classification - Overview (0) | 2021.08.24 |
| [Boostcamp 3주차] 피어세션과 학습 회고 (0) | 2021.08.20 |
| [Boostcamp Day-14] PyTorch - Multi_GPU, Hyperparameter, Troubleshooting (0) | 2021.08.20 |