Sequential Model
sequence data에는 소리, 영상, 주가 등의 시계열(time series) 데이터가 있다. 일반적으로 1개의 label을 얻는다고 했을 때 CNN의 경우 정해진 크기의 값이 FC Layer를 통해 출력을 얻지만 sequence data경우 길이나 사이즈가 달라지고 과거의 정보 없이 미래를 예측하는 것이 어렵다. 그렇기 때문에 RNN(Sequential Model)을 사용하게 된 것이다.
Naive Sequence Model
우선 간단한 sequential model로 naive sequence model을 살펴보면 다음과 같이 과거의 모든 정보 (x_t-1, x_t-2...)를 담아 예측하는 것으로 이해할 수 있다. 예를 들어서 첫 번째 단어가 입력되면 두 번째 단어는 첫 번째 단어, 세 번째 단어는 두 번째를 고려하여 예측하게되는데 이렇게 모든 데이터를 고려하게되면 시간이 길어질수록 상당히 많이 증가하게 된다.

Autoregressive Model
이 모델은 naive sequence model에서 모든 과거의 데이터를 고려하는 것과는 달리 몇 개의 데이터만 고려하여 예측하겠다는 방법이다. 예를 들어 과거의 10개 데이터만 보겠다면 아래 그림에서 τ의 값이 바로 10이 되는 것이다. 다시 말해 x_t-1부터 x_t-τ 의 값만을 고려하겠다라는 것이다.

Markov Model (First-order Autogressive Model)
markov model은 현재의 값 x_t가 직전의 과거의 데이터 x_t-1에만 의존(dependent)하겠다는 가정하에 다음과 같이 정의한 것이다. 하지만 이 model은 현재 시점의 정보가 그냥 바로 이전 과거 정보만 가지고 결정한다는 가정에 문제가 있다. 예를 들어 오늘이 시험인데 어제 공부한 내용에만 영향을 받는 것은 아니라는 얘기이다.

Latent Autoregressive Model
autoregressive model에서 고정된 길이 τ를 활용한다는 아이디어에서 좀 더 나아가 고정된 길이의 데이터를 다루면서 유의미한 과거의 정보를 담는 방법을 고안해낸 것이 Latent Autoregressive Model이다. 다시 쉽게 설명하면 기존 autoregressive model에서는 τ길이를 직접 정해줘야하므로 어느 정도 사전지식이 필요하다. 문제에 따라 먼 과거의 정보들을 고려해야 하기도 하고 τ가 바뀌는 경우도 있다. 이럴때 잠재변수라는 것을 사용하여 design한 모델이 Latent Autoregressive Model이라는 것이다.

위에서 나오는 h_t라는 변수가 바로 Latent Variable(잠재변수)라 불리며 이전의 정보인 x_t-1을 제외한 나머지 정보들을 인코딩하여 이용한다. 따라서 바로 이전의 정보 x_t-1과 잠재변수 H_t 두 가지만 가지고 예측할 수 있기 때문에 고정된 길이의 데이터를 가지고 모델링 할 수 있게된다.
이렇게 잠재변수 H_t를 신경망을 통해 반복 사용하여 sequence data를 학습하는 모델을 RNN이라고 한다.
Recurrent Neural Network

위에서 언급한 것처럼 CNN은 잠재변수 H_t를 사용하여 activation function인 tanh과 같이 다음 H_t+1을 얻는 것을 반복 수행한 후 출력한다. 또한 RNN에서 사용하는 가중치 행렬들은 모두 share하기 때문에 가중치 수를 줄이며 데이터별 시간의 길이에 유연하게 반응할 수 있다.
Short-term dependencies
RNN에서는 다음과 같이 현재에서 과거 몇 개의 데이터를 고려했을 때 잘 되지만 멀리있는 과거의 데이터는 힘들다.

Long-term dependencies
반대로 다음과 같이 멀리있는 과거의 데이터는 진행될 수록 점점 그 내용을 잃어가는 문제가 발생한다.

Long Short Term Memory
Long Short Term Memory는 위에서 얘기한 문제들을 해결하기위해 고안해낸 구조이다. 간단히 말하면 Long Term Memory와 Short Term Meomory를 같이 고려하여 계산함으로서 극복하겠다는 것이다.
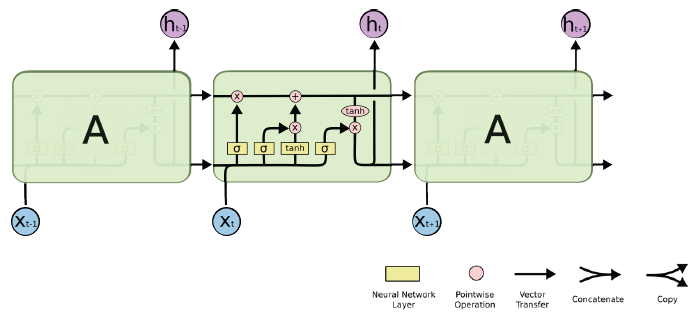
위에있는 A라는 셀의 내부를 자세히 살펴보면 다음과 같은 구조를 가진다.

총 4개의 gate로 이루어져있으며 입력값은 이전 cell state, 이전 hidden state, X_t 3개가 있고 출력은 Next cell state, Next hidden state, h_t 3개가 있지만 실질적은 출력은 h_t가 된다. 여기서 LSTM(Long Short Term Memory)의 핵심은 cell state인데 간단하게 말하면 정보가 변하지않고 그대로 흐르게 해주는 역할을 해주는 녀석이라고 이해하면 될 것 같다.
- Forget Gate

우선 forget gate는 sigmoid layer를 사용하여 입력받은 데이터를 버릴건지 말건지 0과 1로 결정하여 cell state에 넘겨준다. 위에서는 잠재변수 h_t-1과 현재 입력 값 x_t에 각각 가중치를 곱하여 $W_f \cdot [h_{t-1} , x_t] + b_f$로 계산한다. 그 후에 sigmoid 함수를 적용하는 것이다. 수식을 다시 정리하면 다음과 같다.
$$
f_t = \sigma(W_{hf} h_{t-1} + W_{xf}x_t + b_f)
$$
- Input Gate

input gate는 입력값 x_t와 잠재변수 h_t-1에 가중치 행렬을 곱한후 sigmoid를 적용한 i_t와 tanh를 적용한 $\tilde{C}_t$를 얻는다. 여기서 i_t는 sigmoid를 사용하여 현 시점의 중요도를 출력한 값이며 $\tilde{C}_t$로 정규화 작업을 시키고 cell state로 추가할 candidate를 결정한다.
$\tilde{C}_t$에서 tanh를 해주는 이유는 i_t에서 나온 0~1값으로 vanishing/exploding gradient problem이 일어날 수 있기때문에 -1~1값으로 정규화하는 것이라고 한다. 또한 cell state에 추가할 candidate를 결정하기위해 사용한다고 한다.
- Update Cell

forget gate에서 얻은 f_t값은 이전 타임 스템의 cell state 값 C_t-1과의 곱셈을 한다. 그리고 input gate에서 얻어진 C_t은 이전에 설명한 것처럼 sigmoid의 결과값 i_t과 곱셈을 한다. 그리고 이 두 개의 값을 더하면 cell state가 update된다.
- Output Gate

output gate는 update gate를 통해 얻은 C_t를 tanh에 적용하고 잠재변수 h_t-1과 입력값 x_t에 가중치 행렬을 곱한 값 o_t를 simoid에 적용한다음 곱한다. 그러면 tanh 함수로 인해 -1~1 값이 출력될테고 이 출력된 값 h_t는 다음 hidden state의 잠재변수로서 쓰이게 된다.
정리하자면 이렇다. Forget Gate를 통해 과거의 정보를 얼마나 반영할지를 결정하고 Input Gate를 통해 현 시점이 실제 가지고 있는 정보가 얼마나 중요한지를 반영 한 후에 과거의 정보와 현 시점의 정보 중요도를 반영하여 Update한다. 마지막으로 Output Gate를 통해 update된 cell state(과거의 중요한 모든 정보)를 hidden state(다음 타임 스텝에 당장 필요한 정보)로 출력할 값을 만든다.
Gated Recurrent Unit(GRU)
GRU는 LSTM과 달리 cell state가 없고 오직 hidden state로만 이루어져있으며 reset gate, update gate 두 개의 gate만 존재하는 간략한 구조이다.

여기서 중요한 점은 update gate가 이전 LSTM의 forget gate와 input gate를 합쳤다는 것이다. 일단 reset gate부터 하나씩 살펴보자.
- Reset Gate
reset gate는 과거의 정보를 적당히 리셋시키는 gate로 입력값 x_t와 이전 hidden state의 잠재변수 h_t-1을 어떻게 합칠 것인지 결정해준다. 위 수식에서는 r_t에 해당된다.
- Update Gate
update gate는 위에서도 언급했듯이 LSTM의 forget gate와 input gate를 합친 것으로 과거와 현재의 정보를 얼마나 반영할지 결정하는 gate이다. sigmoid를 적용하여 출력된 z_t가 바로 현 시점 정보의 중요도이고 1 - z_t를 통해 과거 정보의 중요도를 얻을 수 있다.
- Candidate
reset gate의 결과를 tanh에 적용하여 현 시점의 정보 candidate를 얻는다.
- Update Hidden State
얻은 candidate와 update gate의 결과를 이용하여 현 시점의 hidden state 정보를 update하게 된다. 즉, 과거의 중요한 정보$((1-z_t)*h_{t-1})$와 현 시점의 중요한 정보$(z_t * \tilde{h}_t) $를 더한다는 것이다.
'Boostcamp AI Tech' 카테고리의 다른 글
| [Boostcamp Day-10] DL Basic - Generative Models (0) | 2021.08.13 |
|---|---|
| [Boostcamp Day-9] DL Basic - Transformer (0) | 2021.08.13 |
| [Boostcamp Day-8] DL Basic - Computer Vision Applications (0) | 2021.08.12 |
| [Boostcamp Day-8] DL Basic - Modern CNN (0) | 2021.08.11 |
| [Boostcamp Day-8] DL Basic - Convolutional Neural Networks (0) | 2021.08.11 |